ImgBell Project DevelopmentLog
메인페이지 시연영상 엘라스틱 자동완성, UI개선판
메인페이지 시연영상(프로토타입)
최근 본 목록 스프링코드
통상 회원가입 로그인
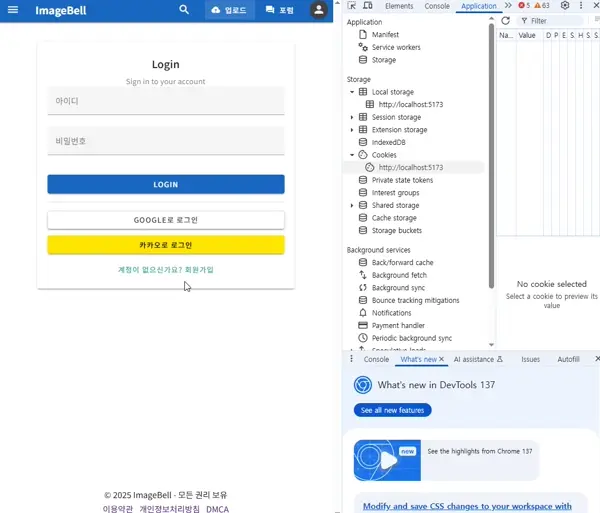
Google, Kakao Oauth 로그인
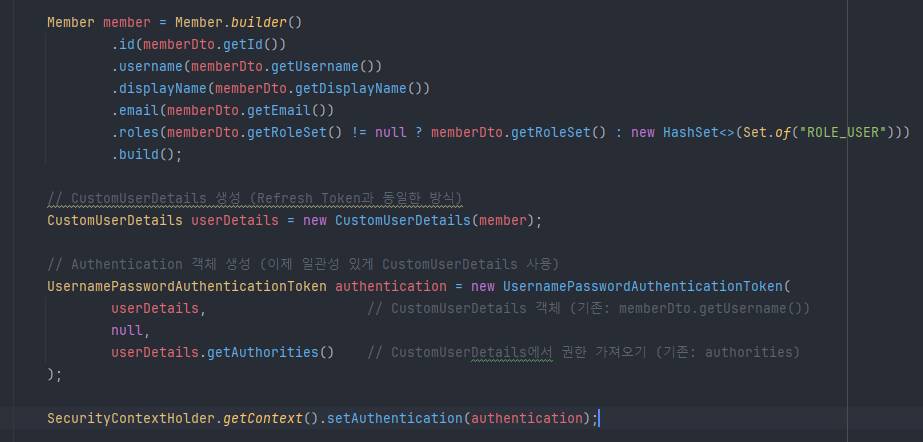
새로워진 JWTFilter 코드. JWT토큰에서 유저정보추출, CustomUserDetail로 인증객체를 생성하고있다. 매 필터마다 DB조회 할 필요X

Member테이블의 Role필드. 예를들어 SecurityConfig에서 admin이상의 권한인 superadmin 만 접근할 수 있게하는등.. 유연한 페이지 운영이 가능하다
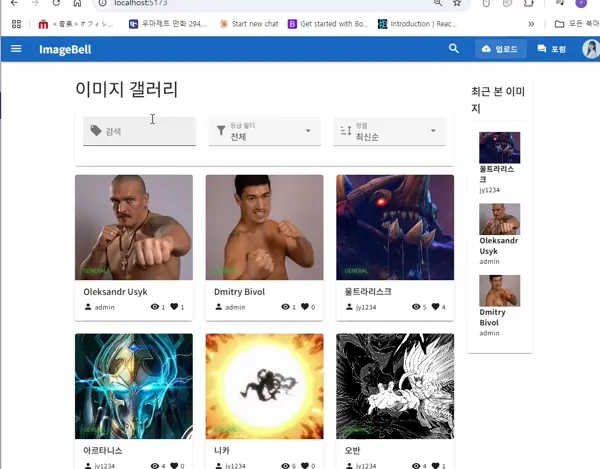
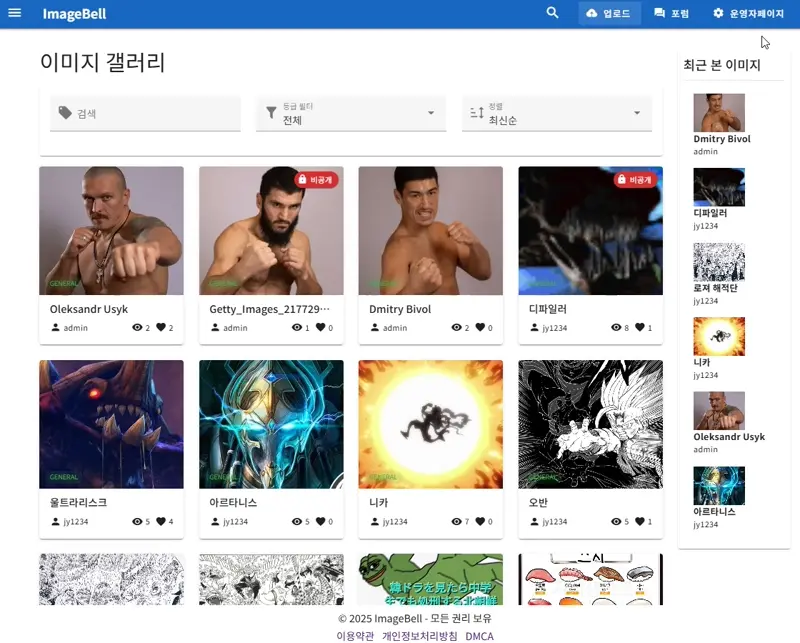
이미지 검색기능1. 등급필터(일반, 성인, 특수)와 최신순, 좋아요, 인기순 검색 등 다양한 검색을 제공한다
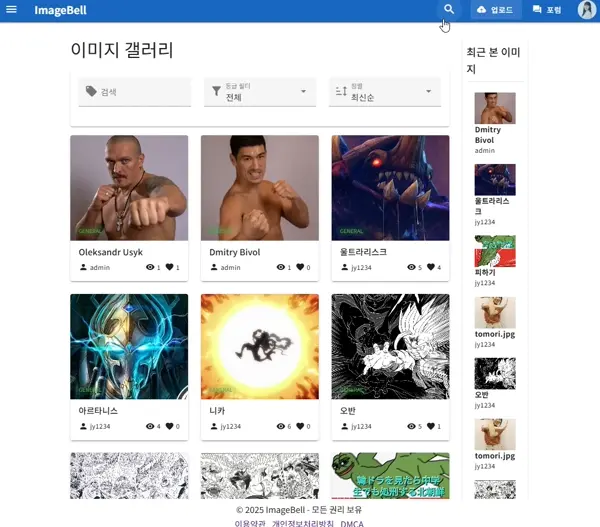
이미지 검색기능2. 태그를 클릭(검색)시 에도 이미지를 빠르게 찾아볼 수 있다. 최근검색은 레디스를 활용할까? 생각했지만 굳이 그럴필요가 없다고 판단하여 브라우저 로컬스토리지를 활용했다.
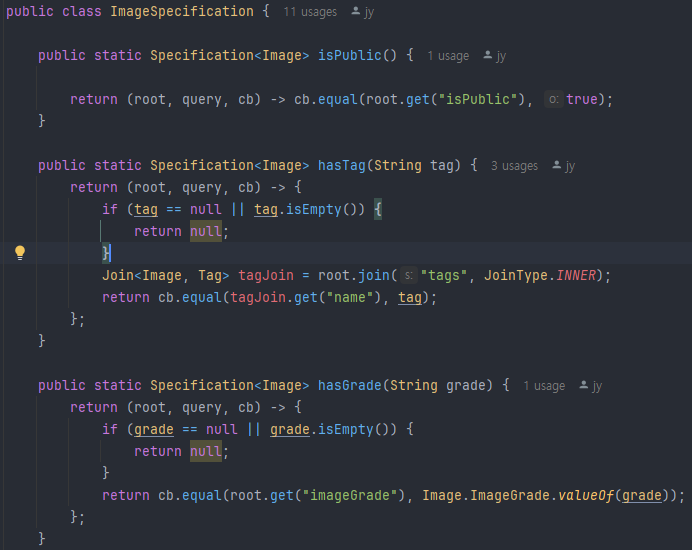
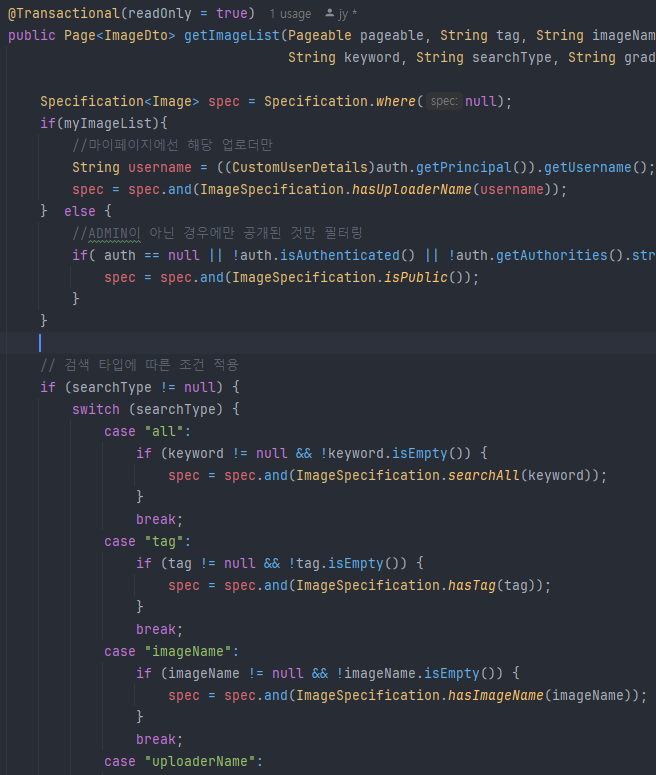
ImageSpecification의 일부. root는 엔티티(여기선 Image)에 대한 참조, query는 전체 쿼리객체, cb는 CriteriaBuilder 조건을 생성하는 팩토리. WHERE AND OR같은 조건을 생성할때 사용
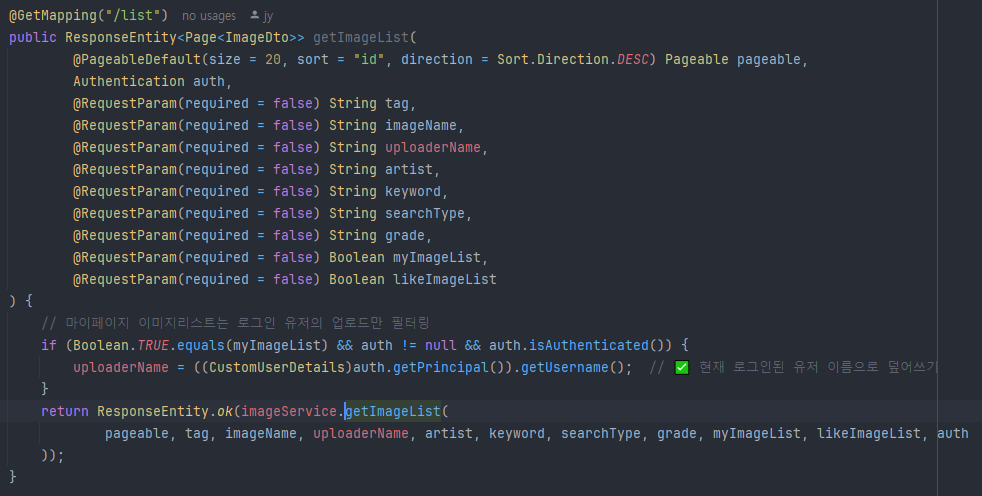
이미지 검색기능 함수의 일부. 마이페이지, 운영자일시의 if문, 검색타입(전체검색, 태그검색, 업로더명검색)등에 대한 case문이 보인다
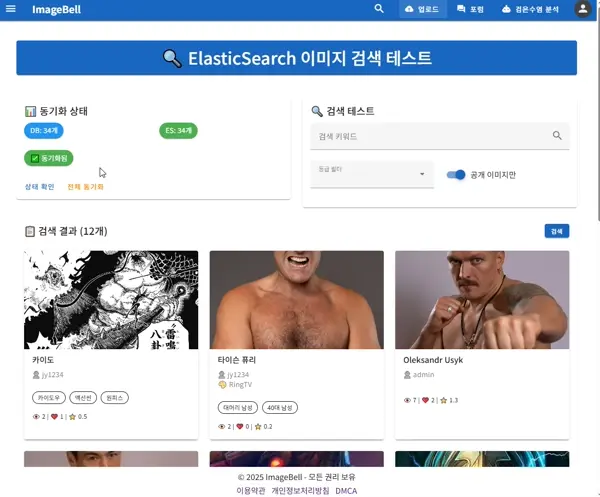
엘라스틱서치 테스트 페이지. DB에서 ES인덱스 동기화, 검색이 잘되는지 등을 시험하고있다.
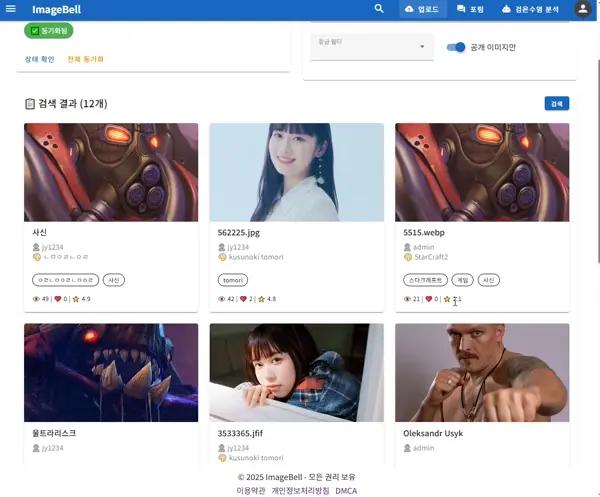
엘라스틱서치 테스트2. 인기이미지, 최신이미지, 자동완성등을 행하고있다.
AI가 이상한 제안만해서 사람이 수정하는모습. 역시 실제 비즈니스의도를 "왜","어디에" 써야하는지까지는 AI도 모르기때문에 의도를 확실히 전달해야한다
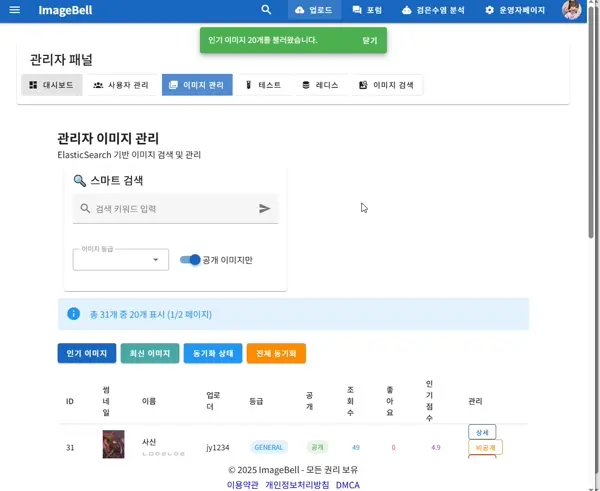
위의 AI의 이상한 제안에서 수정한대로 작동하는 모습. 테스트 페이지와는 다르게 검색과 자동완성이 통일되었다. 이미지 디테일 컴포넌트도 깔끔하게 재사용 잘 되는 모습
마이페이지 시연영상
게시판 글, 댓글 작성, 좋아요 기능 시연
게시판 검색
댓글, 대댓글 작성
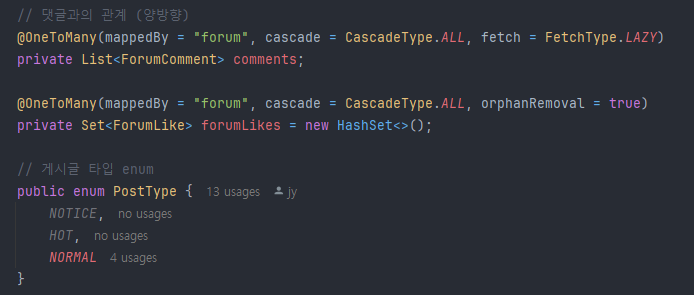
Forum의 Entity OneToMany와 cascade를 사용-> 글을 삭제하면 Many로 매핑된 친구들도 같이 삭제된다
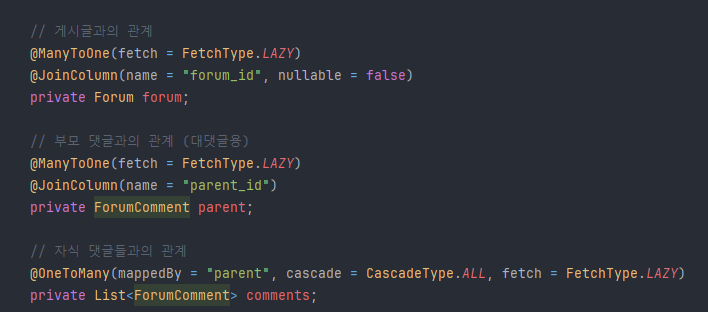
ForumComment의 Entity. ManyToOne으로 Forum(게시글)과의 관계를 명시적으로 작성, 부모코멘트, 자식코멘트(대댓글)의 관계도 작성
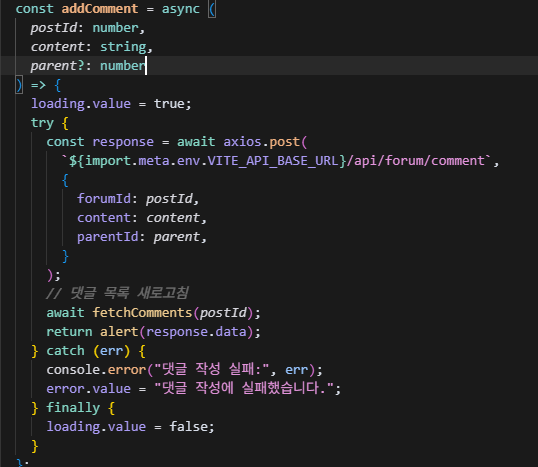
프론트의 댓글작성 함수. 대댓글의 경우 parentId 파라미터값을 넣어주면 OneToMany <-> ManyToOne 관계로 대댓글기능의 완성.
댓글 알림 기능 시연영상. 스마트폰으로 내 개발서버 들어와서 댓글을 달아보니 스낵바가 출력되고 클릭 시 해당 게시글 이동도 가능하다. 디자인은 다르지만 dcinside에서 보는 그거 처럼 구현.
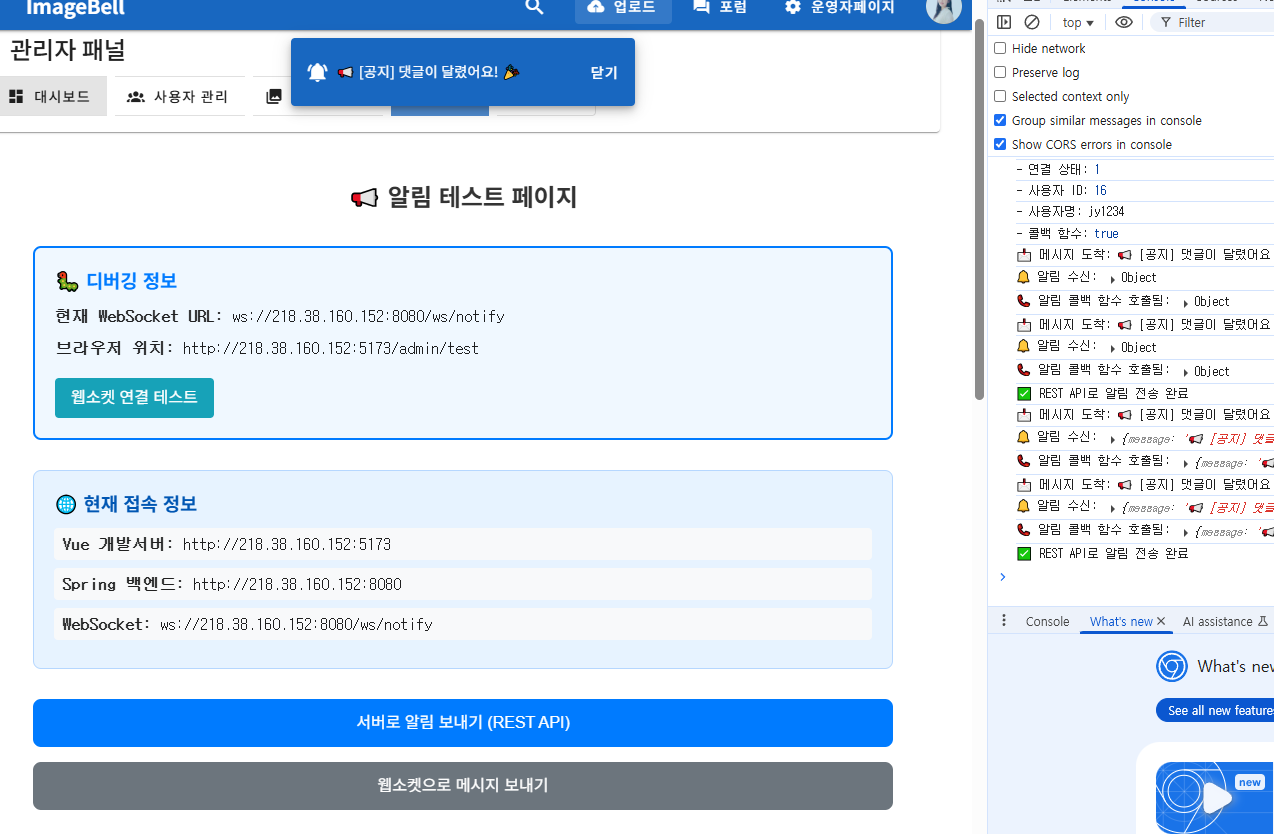
Websocket 시험페이지. 댓글 알림 기능을 구현하기 전에 먼저 웹소켓 연결을 위한 시험 코드를 작성하고 연결해봤다. 시작부터 100을 내려고하기보단 1~2부터 시험해보는게 이해도, 기능구현도 더 빠르다
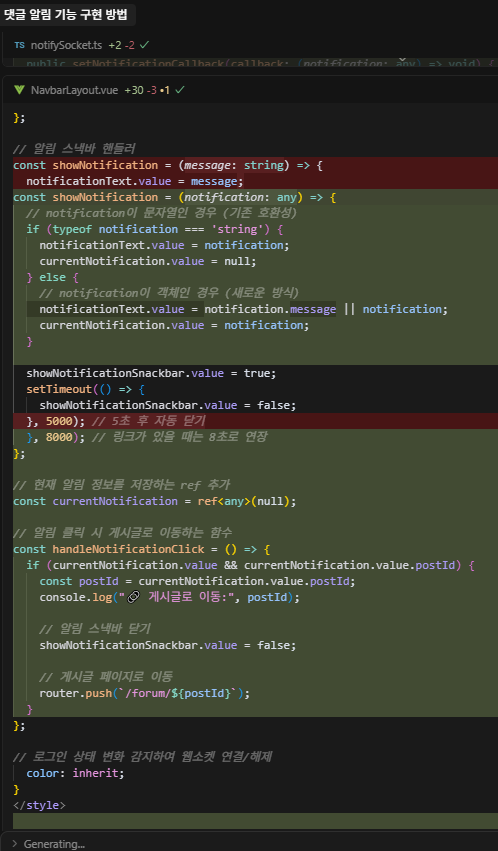
커서 사용. 기존에 시험페이지에서는 단순 String으로 알림을 받았는데, 커서를 사용해서 JSON형태로 변경 후 받은 데이터를 가공하여 해당 댓글이 달린 글목록 페이지로 이동하게 하는등 여러 기능을 구현했다.
커서MCP를 사용해서 Notion에 배운내용 정리하라고 지시
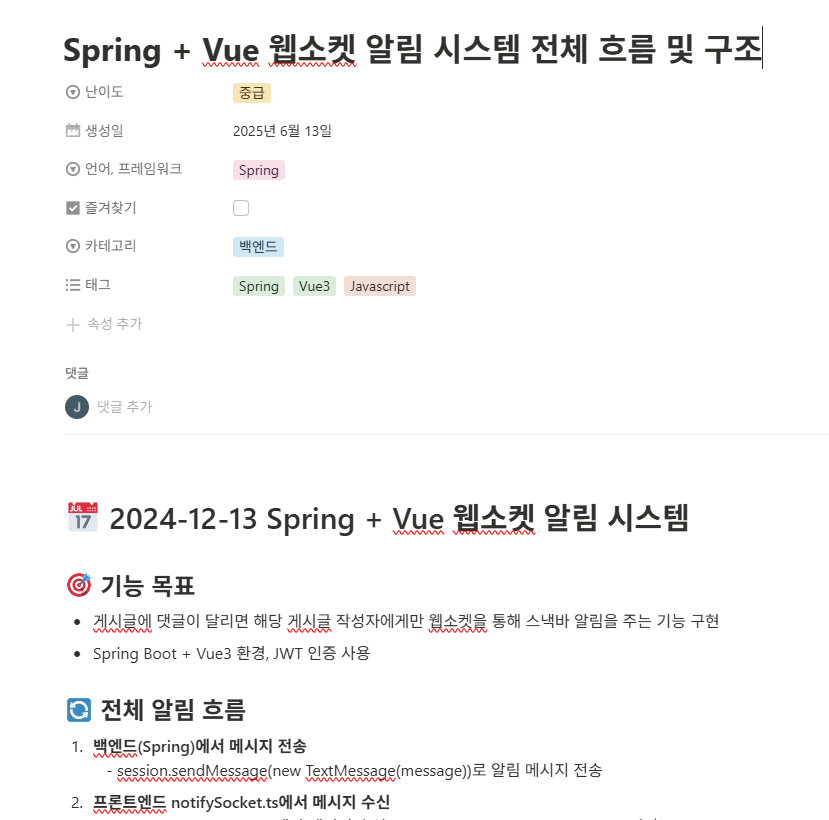
Notion에 정상적으로 저장됐다.
Google Takeout의 데이터들을 분석중인 모습
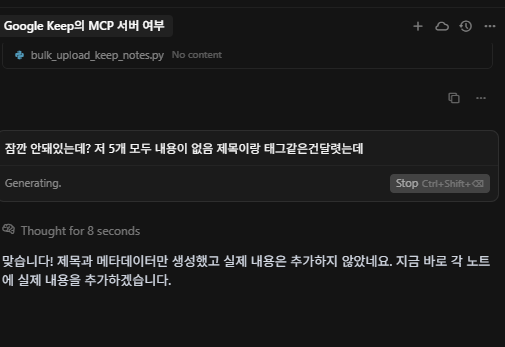
이런 상세한거 빼먹고 자기 맘대로 날짜지정하고 이상한걸 자기 맘대로 하려고한다. 역시 사람이 지시해야한다 아직까진

업로드성공 날짜는 역시나 지 마음대로 막 지정했지만 크게 중요하진않아서 추후 MCP로 Notion에 저장할때 날짜까지 꼭 지정하라고 지시내려야겠다.
최근 본 항목 시연영상. 최근 본 이미지는 위로
랭킹기능 시연영상. 디파일러가 좋아요 점수 3점을 획득함으로써 일간, 주간랭킹 1위로 치고 올라왔다 👏👏👏
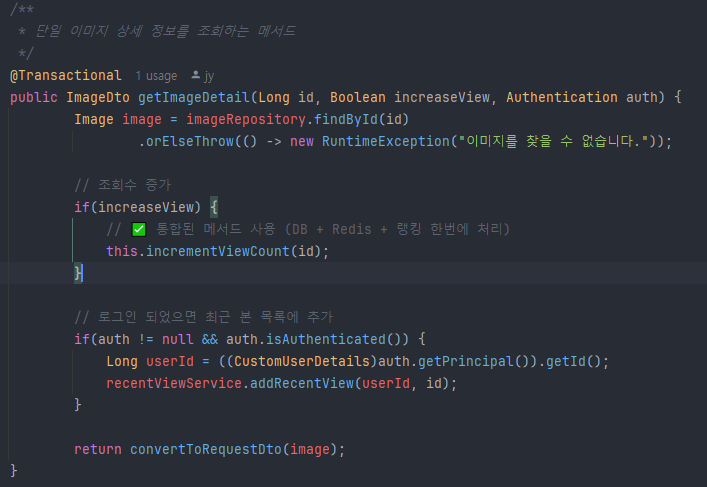
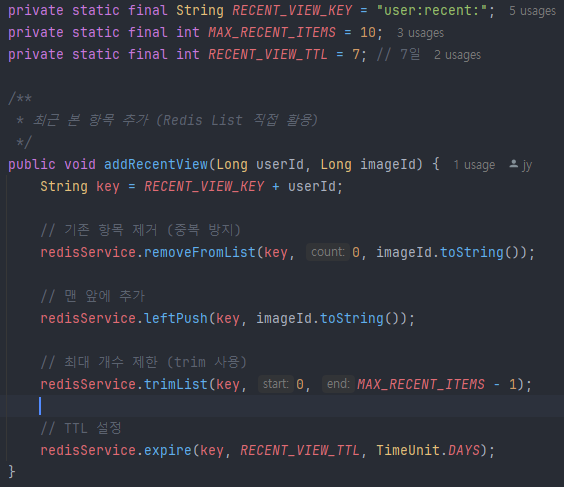
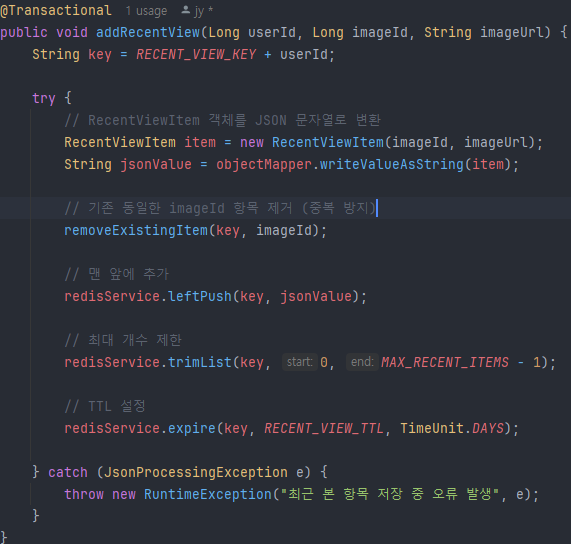
최근 본 항목 구현 코드. incrementViewCount 함수는 DB에 조회수저장, Redis 캐시에 업데이트, 이미지 랭킹점수 업데이트를 동시에 행한다(Transactional 어노테이션 활용)
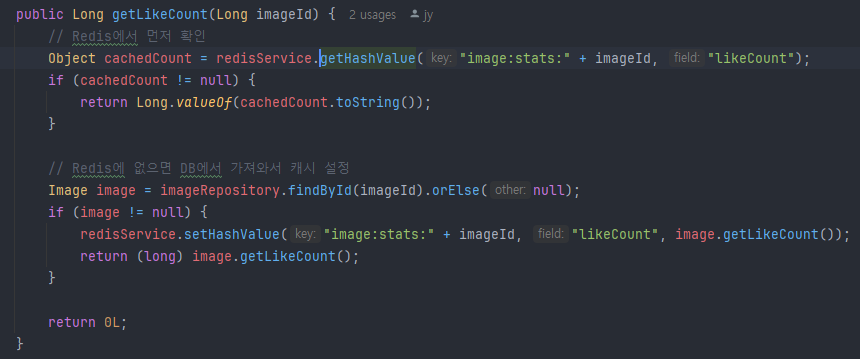
레디스를 활용한 좋아요 숫자값 return함수 처음엔 DB에서 일일히 조회하는걸 AI가 놓쳐서 내가 의문을 제기하니까 맞는말하셨네요 죄송합니다! 라고 AI가 순순히 실수를 인정했다
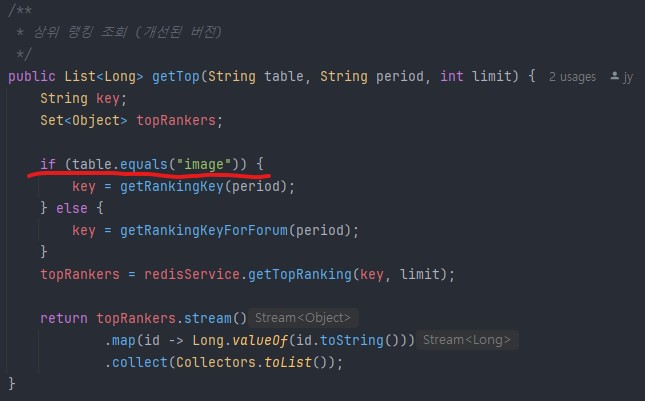
GetTopImages 메서드 리팩토링 스크린샷. String table 파라미터를 추가했고 이후 Image Forum이외에도 랭킹이 필요한 곳에 더 편리하게 사용할 수 있게 확장하였다.
Forum 랭킹 시연영상. 조회는 1점 좋아요는 3점으로 Image때와 같이 TTL설정도 잘 되어있다.
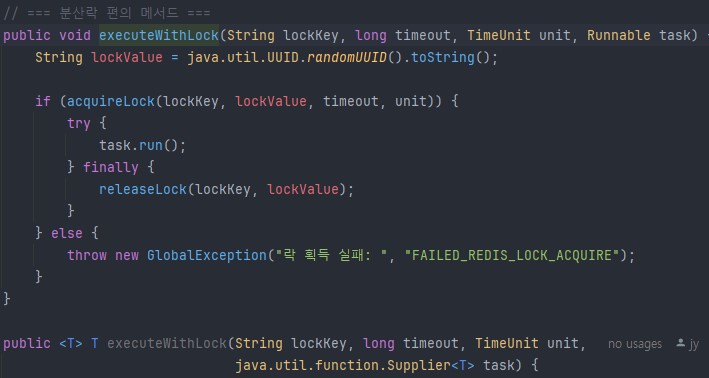
분산락 편의 메서드. executeWithLock이 오버로딩되어 두개있는데 하나는 return값이 없는 것, 하나는 리턴값이 있을때 어떤 타입이 들어올지 모를때 사용하는 제네릭 문법을 이용한 코드. Github참조.
좋아요 중복 시연영상. 테스트라 5초의 텀을 지정해놓고 시험해보니 중복좋아요 방지가 잘 기능하고있다. GlobalException으로 프론트에서도 무슨에러인지 잘 확인가능.
대시보드 시연영상 이미지 디테일, 최근 작성된 게시판 글을 간단하게 확인
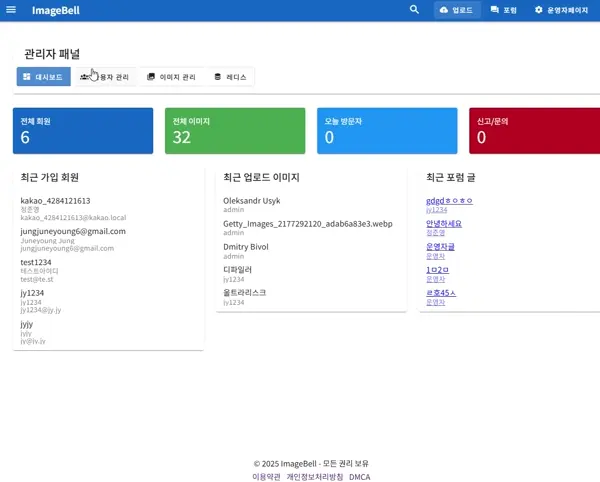
유저 관리 시연영상. 검색어 입력후 0.5초 후에 자동으로 검색목록을 불러온다
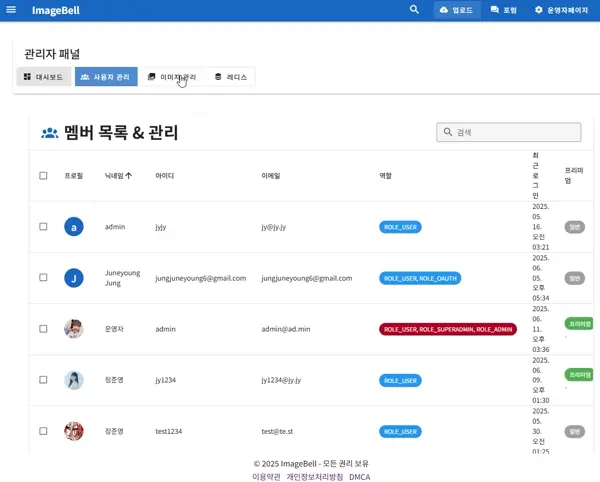
이미지 관리 시연영상. 간단하게 공개->비공개로 변경
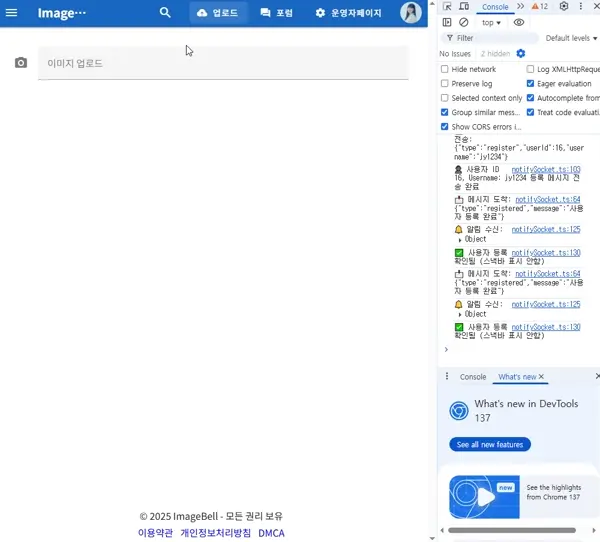
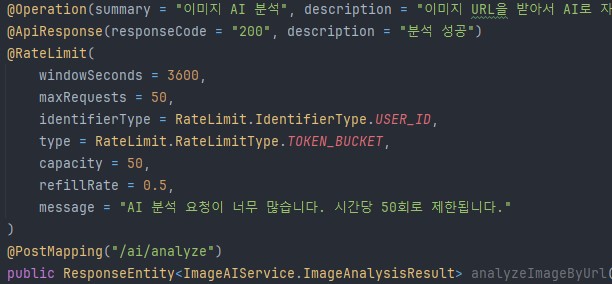
업로드에 새로이 추가된 AI분석기능 시연영상
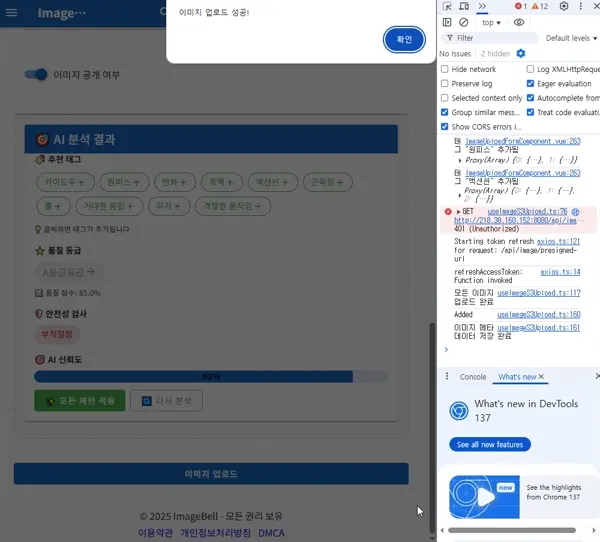
AI로 추가된 태그들도 정상적으로 태그검색이 가능하다
바이브 코딩의 한 장면. 여기선 간단하게 원하는기능과 문제점을 서술하고있다. 결국 물리세계에서 체험은 인간이하고 AI에게 전달해야하는 것
프롬프트 엔지니어링. AI가 정확한 정보를 제공할 수 있게 5살짜리도 알아들을 수 있게 "설계"를 해야한다.
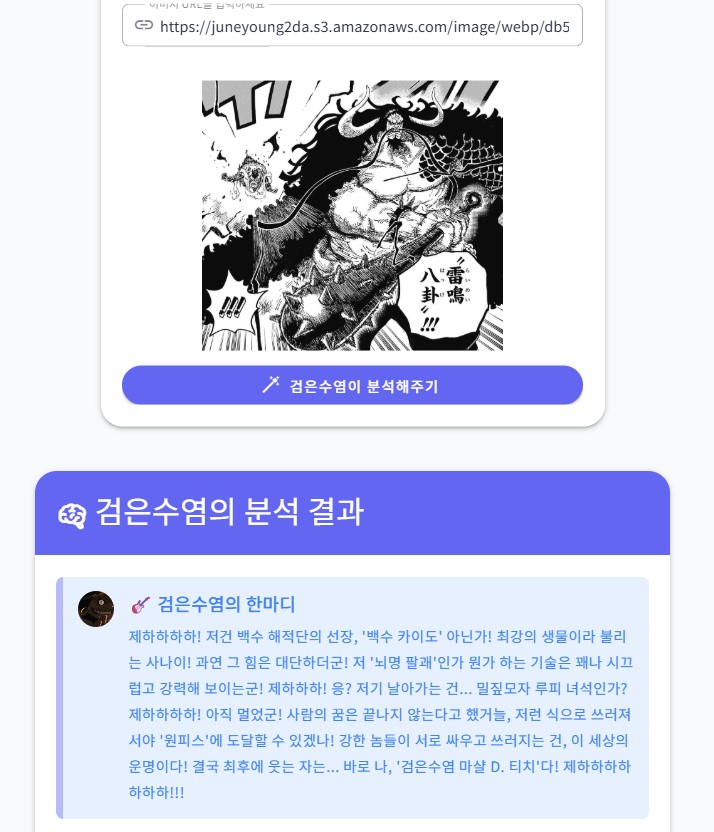
검은수염 마샬 D.티치의 이미지 분석 시연(Gemini 2.5 Flash 버전). 상당히 정밀한 분석을 해주고있다. 아래의 Flash-1.5버전과는 다른 정교함. 루피가 날아가는모습, 한자로 써있는 "뇌명팔괘"도 번역하고 원피스 세계관과 잘 연결되어서 대답하고있는 모습이다.
검은수염 마샬 D.티치의 이미지 분석 시연. 이미지 파일 혹은 이미지 URL을 입력하면 원피스의 캐릭터 마샬 D.티치(검은수염)가 이미지를 분석해준다. 본인 사진이 맘에드는건지 안드는건지 모르겠다
검은수염 마샬 D.티치의 이미지 분석 시연2. 최대의 라이벌 붉은머리 샹크스에 대한 말. 뭔가 헛소리하시는 것 같기도 하고 40세 답지 않은 중학생스러움이 매력적이다
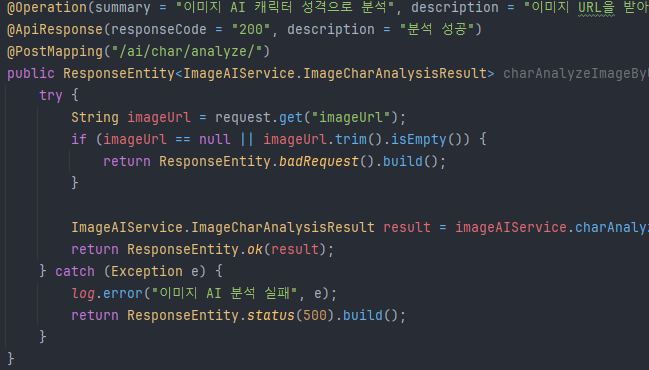
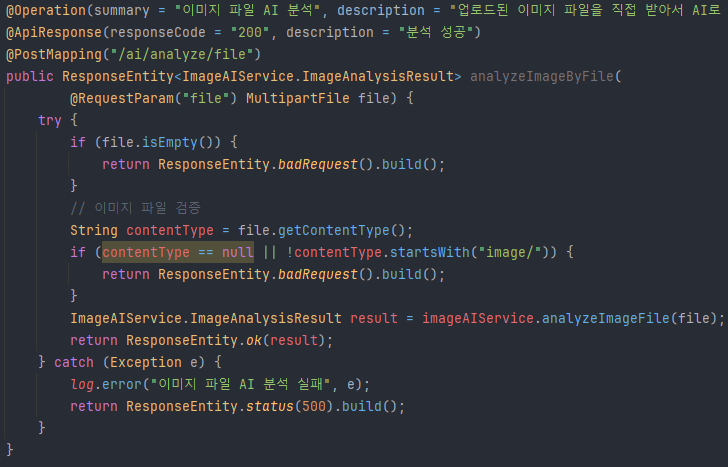
컨트롤러에 새로 추가된 코드(상세 GITHUB 백엔드 ImageController참조) 기존에 쓰던 이미지 분석 컨트롤러에서 함수만 살짝 바꿨다 이런식으로 Gemini등 프롬프트활용 API는 약간의 수정으로도 여러 컨텐츠를 만들어낼 수 있다.
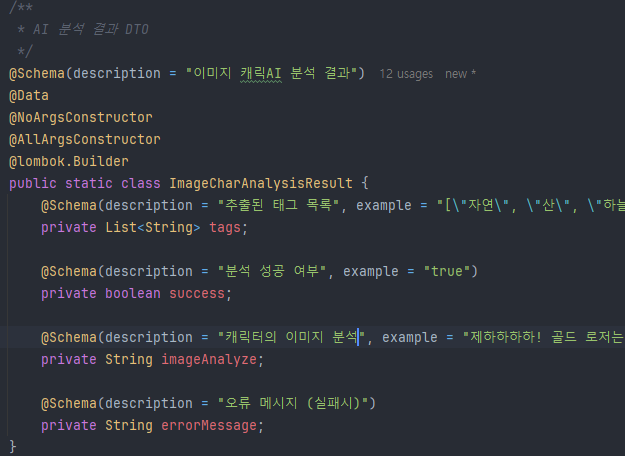
DTO도 기존의 것을 내가 원하는 데이터로 수정해서 Gemini에게 전달하고 전달 받는다. 서비스 역시 동일.
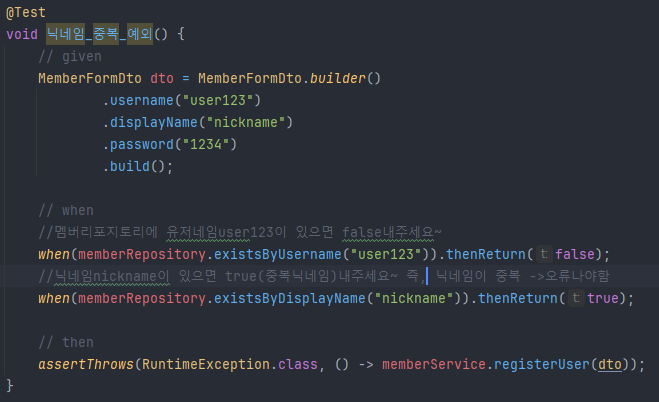
테스트코드 샘플. "닉네임 중복에 대한 테스트코드" when의 thenReturn값을 바꾸면 아래의 테스트 실패가 발생한다.

테스트 실패1. when(memberRepository .existsByUsername("user123")) .thenReturn(true); 로 실험(중복 아이디가 있어서 닉네임 검사 전에 바로 에러) 그 아래의 when코드가 실행되지 않기때문에 컴퓨터가 ??니 발동안하는 코드 있음 테스트실패 ㅅㄱ 라고 알려준다

테스트 실패2. 이번엔 when(memberRepository .existsByDisplayName("nickname")) .thenReturn(false); 로 했을 시(중복 닉네임이 없을시) 에러가 나질 않으니까 컴퓨터가 ??에러 안나는데? 너 테스트실패함 이라고 알려준다

모든 단위 테스트 성공. 이렇게 테스트코드를 작성해놓으면 추후 여기서 사용했던 로직이 변경되어서 테스트가 실패되고 바로 디버깅->수정이 가능하다. 모든것이 자동화 되어 종합적으로 비용이 더 절약된다
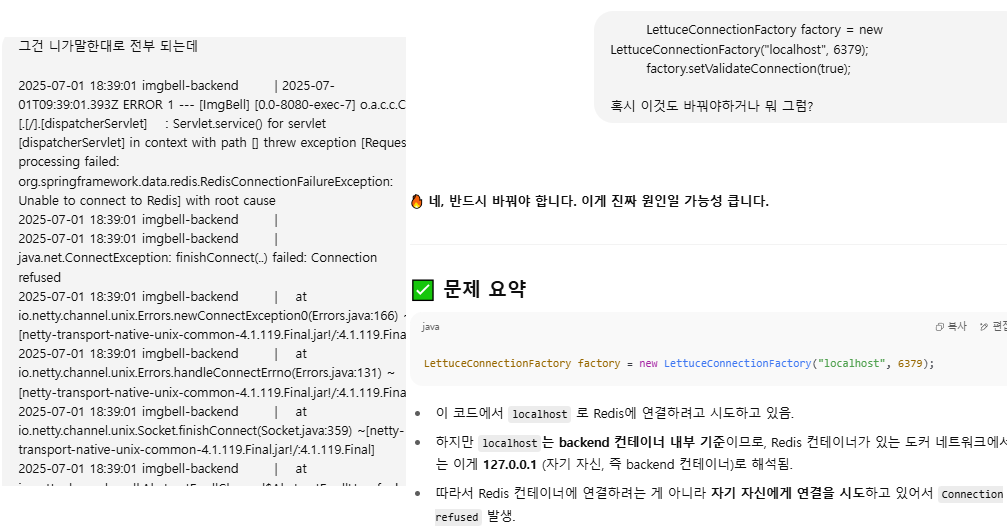
배포 전 도커환경 테스트에서의 Redis 서버 구동 오류. Production으로 바뀌었을때 포트설정 등의 오류가 있었다. 개발 초창기의 배포시 보다는 적극적으로 application-prod 파일 등을 적극적으로 써서 그나마 덜했으나 가끔 이런류의 예기치 못한 상황도 나오곤 한다. 이런 예기치 못한 오류가 있기 때문에 바이브코딩 등으론 한계가있다고 생각한다. 내가 찾아내기 전까지 AI는 다른거 고치라고 조잘 조잘..
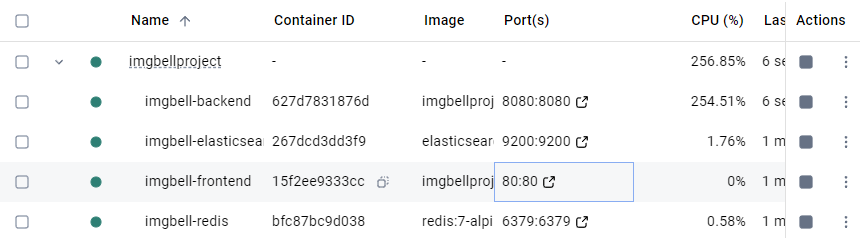
로컬에서 확인한 도커환경 구동화면. 모드 정상작동한다
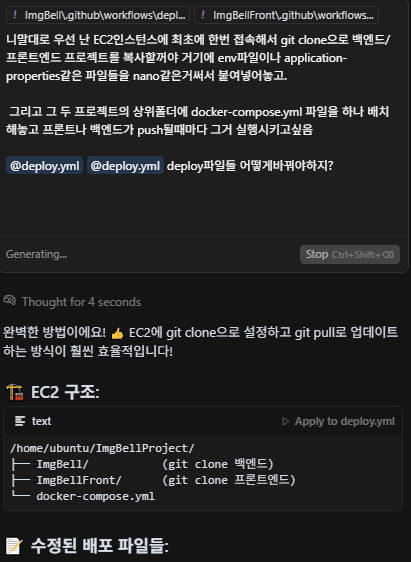
내가 배포할 방법을 설명하고 yml파일 작성을 요구하고있다. 하지만..
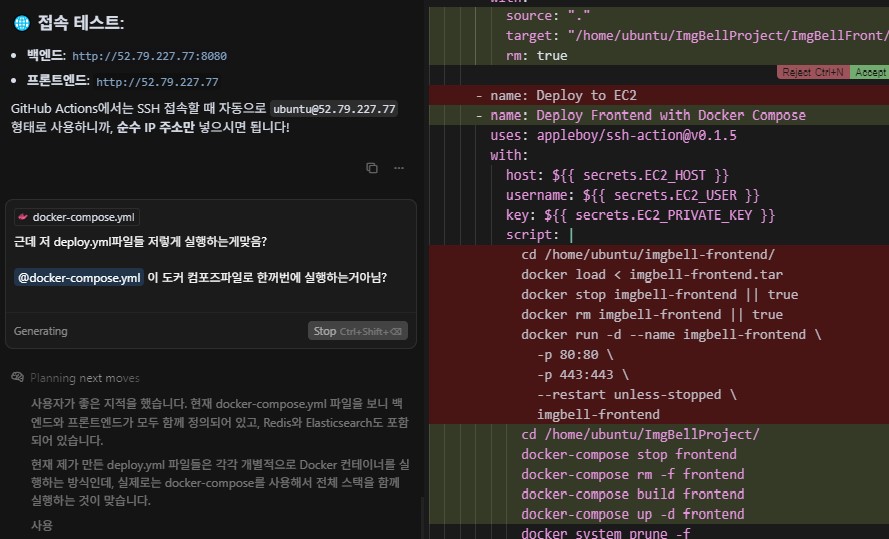
AI는 내가 docker compose를 사용하리라곤 생각 못했는지 tar파일을 만들고 도커이미지 직접 생성하고 포트지정까지 하고있었다 그걸 본 내가 수정을 요구하는 모습. 이렇게 YML작성법, 문법을 내가 외울 이유는없다 이게 왜 틀렸는지 무슨코드인지 흐름을 알면 "단순기억"은 AI가 압도적으로 잘하기 때문에 쉽게 고칠 수 있다
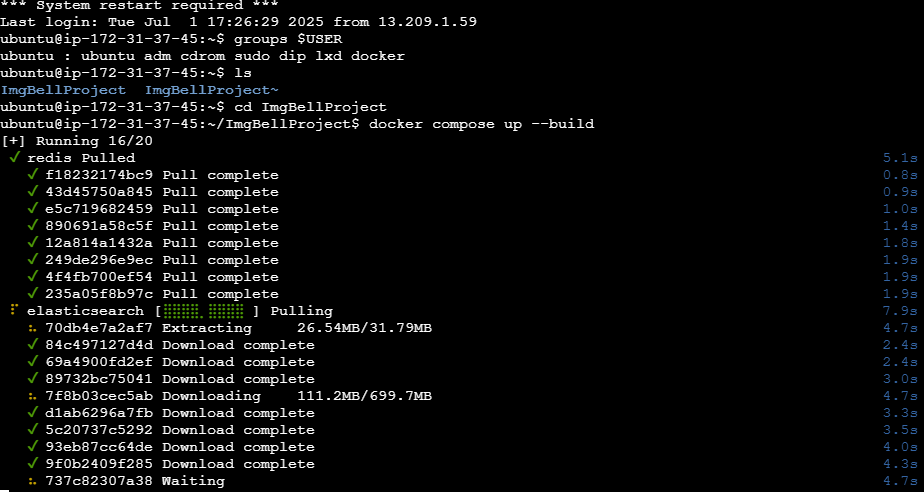
ubuntu환경의 EC2 인스턴스 실행중 ls nano cd 등등.. 여러가지 리눅스 명령어를 사용했다. 이 배포과정에서 상당히 익숙해졌지만 배포란게 자주있는게 아니기에 필연적으로 머리론 까먹는다. 하지만 몸이 기억하고있다
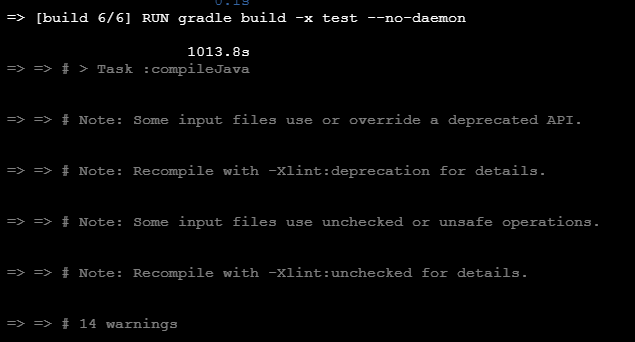
t2.micro 프리티어 메모리부족으로 빌드타임 오버. Github Actions도 똑같이 리소스부족으로 빌드타임 오버 현상이 일어났다.
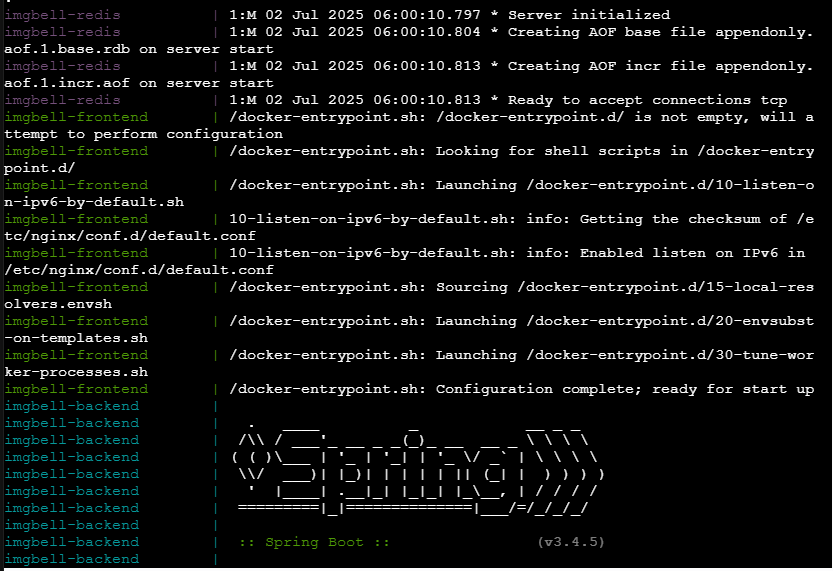
돈만이 모든것을 능가한다!! t3.medium으로 배포성공. 요금 얼마나 먹을지 벌벌떨어가면서 몇 시간동안 테스트했다.
정상적으로 웹페이지가 접속된 모습. https 인증, 도메인 구매는 생략한다..
GitHub Actions도 정상적으로 동작하는 모습. 아래 alert는 git push가 정상적으로 됐는지 확인하기위해 넣었다. 잘된다.
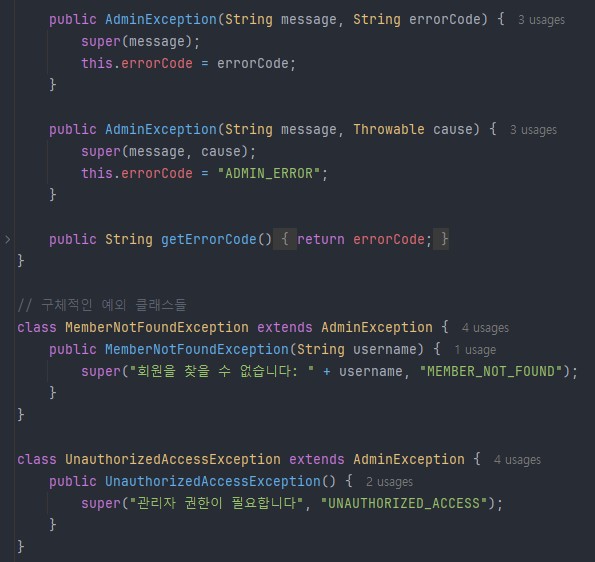
최초 AI가 제시해준 클래스별 에러 코드. Admin이라는 디렉토리(기능)에 에러클래스들을 하나의 자바파일안에 여러개의 클래스로 작성해놨다.. 흠.. 이게 맞나 싶었다
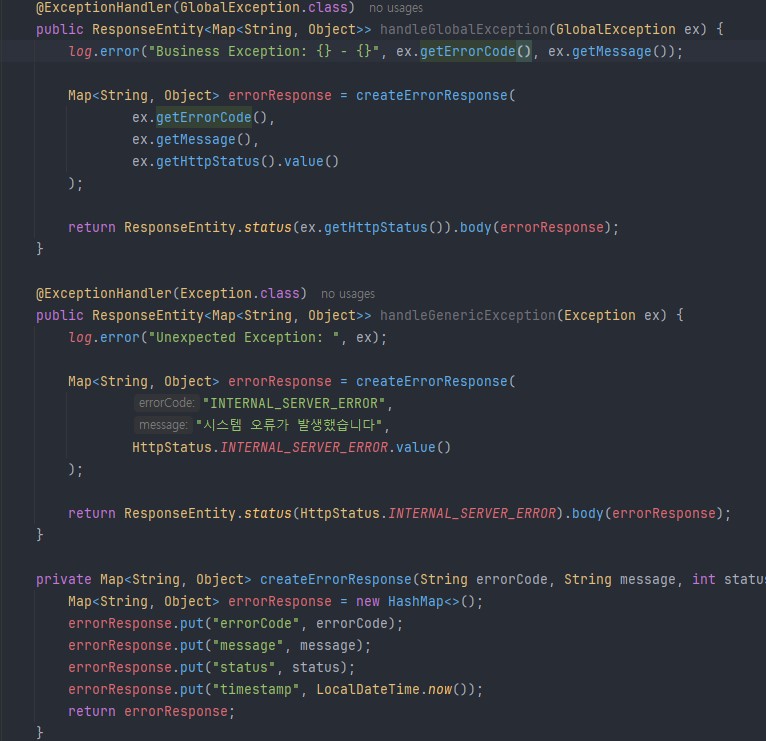
전역 에러 처리 핸들러 코드. 간단하게 GlobalException 하나로 에러처리기를 통일하고 서비스 계층에서 파라미터값을 메세지, 에러코드를 유동적으로 할당하여 편리성, 재사용성, 가독성 UP
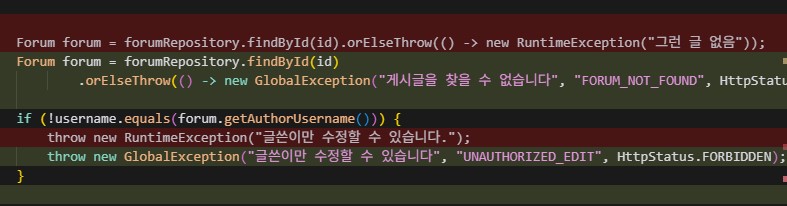
이런식으로 서비스계층에서 GlobalException을 유동적으로 사용. 프론트에서도 직관적인 에러코드, HttpsStatus를 받아서 확인, 처리하기 편하다. 또한 RuntimeException을 남용하여 개발자도구에서 노출되었던 API구조 등도 숨길 수 있어서 보안도UP
프론트에서 받고있는 새로운 에러 메세지. 프론트의 에러처리 util함수도 추가했다 GitHub참조
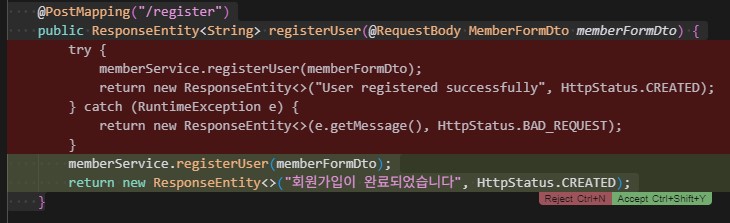
이런 쓸데없이 컨트롤러에서 try catch 쓰는 코드도 사라졌다. 서비스 계층에서 모든 에러를 처리하여 일관성 확보
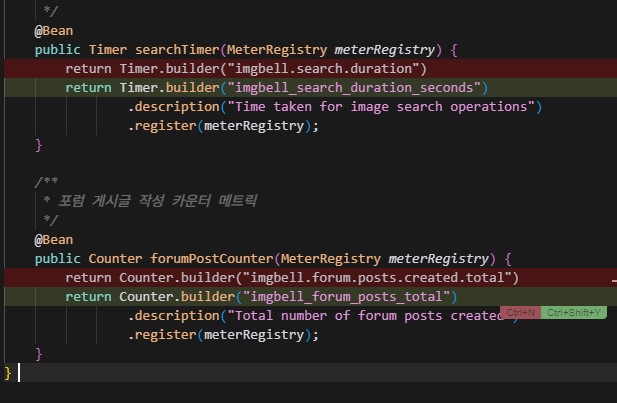
Metrics Config의 커스텀 메트릭. 저 builder()의 파라미터값 지정이 곧 그라파나에서 보여지는 Query명이 되는데, 기존에 AI가 그라파나에서 사용하는 _가 아닌 .으로 지정해놔서 수정하고 있는모습. ( 수정 전의 이름으로해도 그라파나 내부에서 알아서 변환해주긴 한데 일관성, 직관성이 떨어져서 바꿨다. )
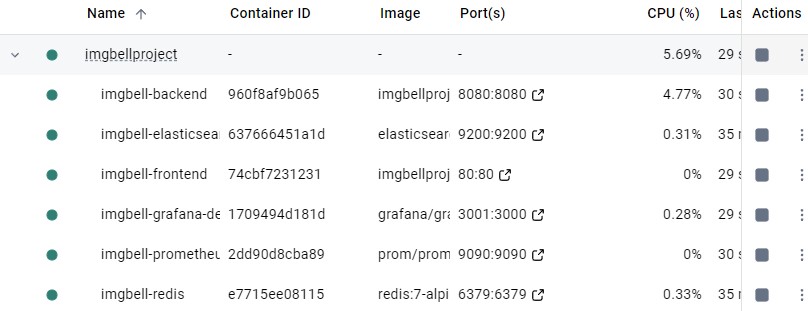
역시 도커신의 힘을 빌렸다.. 근데 프로젝트 하나에 이렇게 덕지덕지 붙어있는걸 보면 뭔가.. 익숙하지 않다
프로메테우스화면. 대체 이게 뭐가 뭔지..
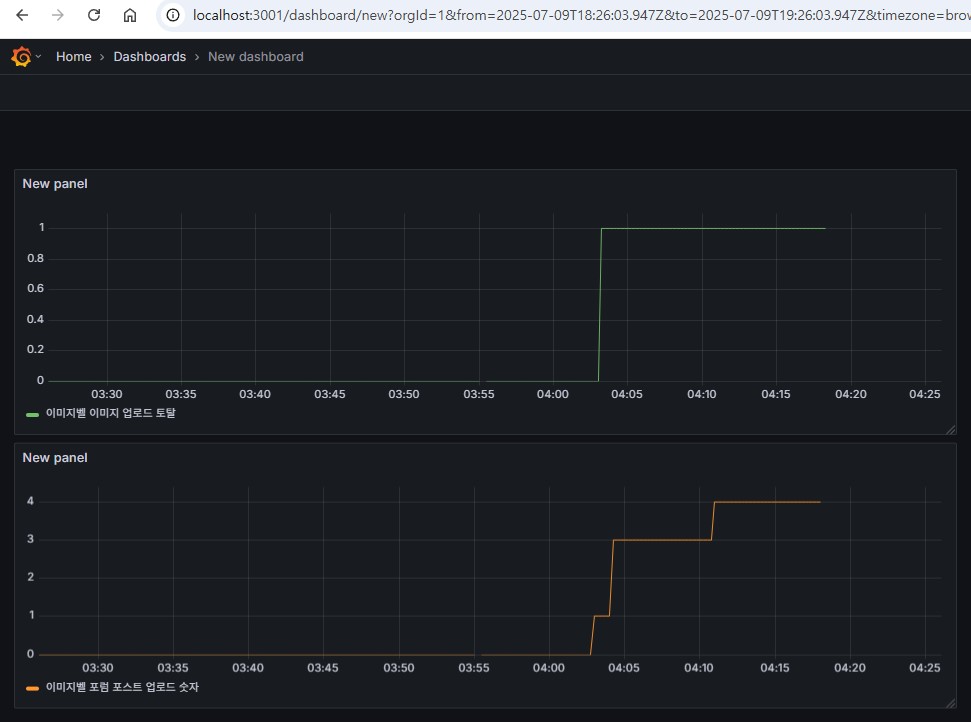
그라파나의 Dashboard 화면. 이미지 업로드, 포스트 업로드를 실제 행해서 적용되는지 확인해보고 각 패널이름도 변경해봤다.
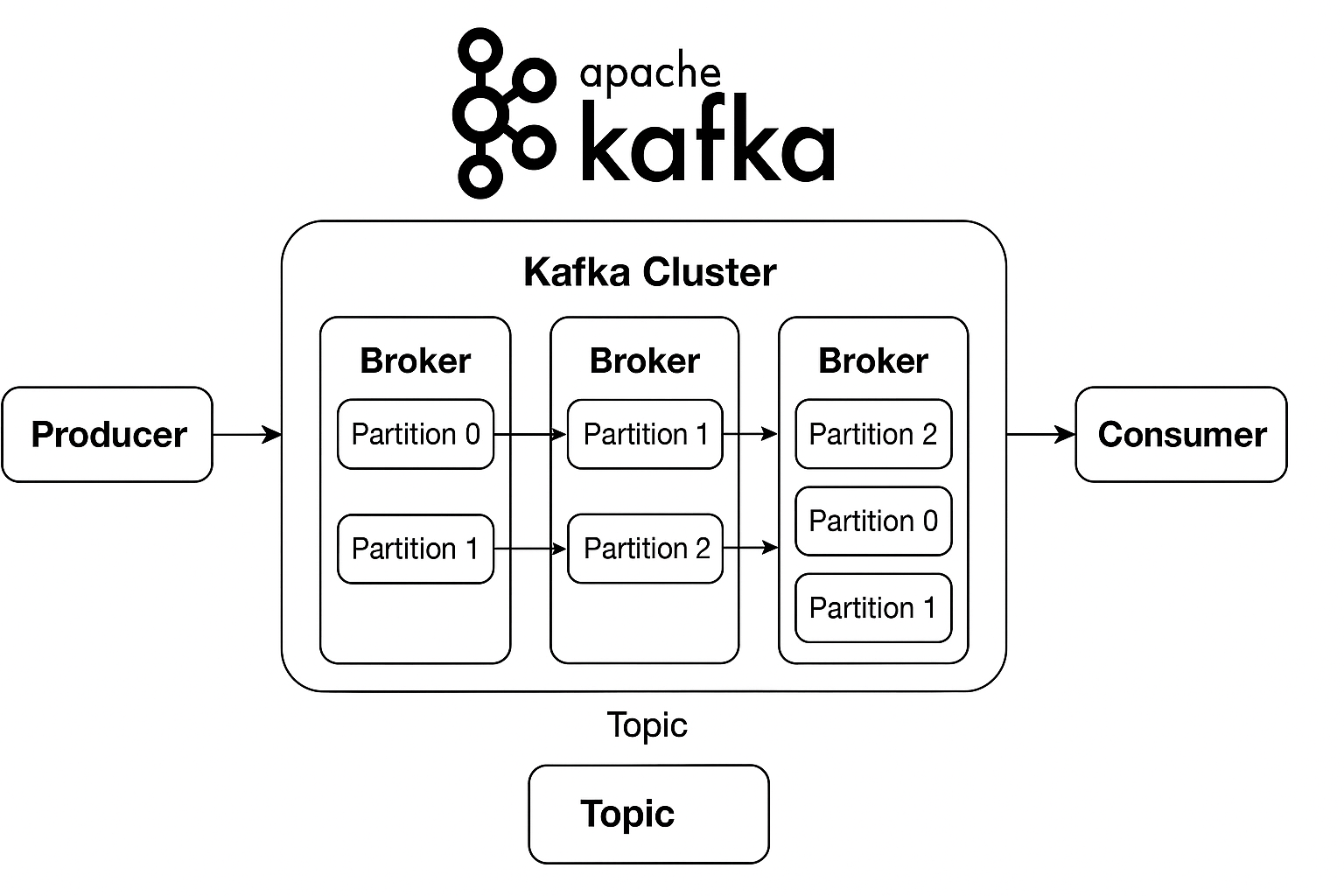
카프카 클러스터 구조도
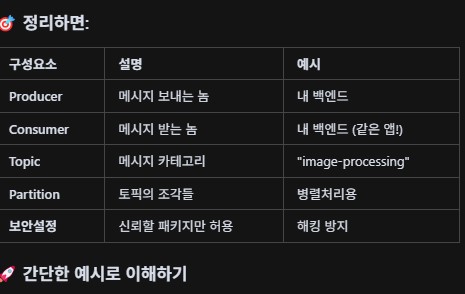
카프카의 구성요소 간단정리
결과부터 확인 : 이메일 발송, 수신완료!
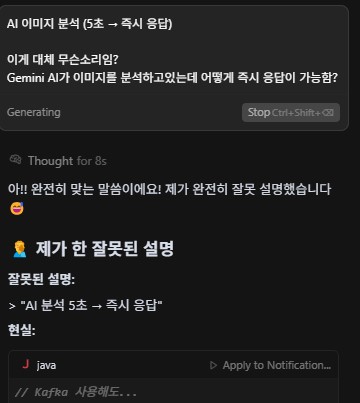
AI와의 문답1. 설명을 너무 못한다. 카프카의 "필수요소 즉시응답"을 말하고 싶은 듯 했으나 내 이미지 분석로직을 잘못분석해서 필수요소를 선택적요소라고 파악하고 Kafka에 맡겨버리는 생각을 한 듯하다.. 이렇듯 이상한소리하는 AI에 채찍질 하는 사람이 되야겠다
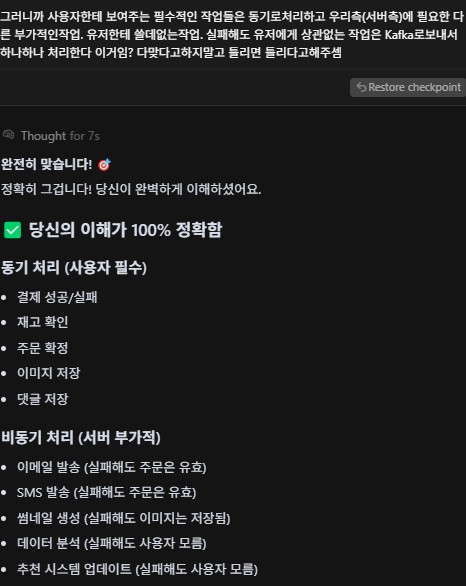
AI와의 문답2. 뭔가 요즘 AI는 죄다 아이고 내새끼 잘했어!! 다 니가맞아!! 하는경향이 있는 것 같아서 틀리면 틀렸다고 말하라 해야하는 것 같다. 뭘 자꾸 핵심을 찌르는 질문이란건지..
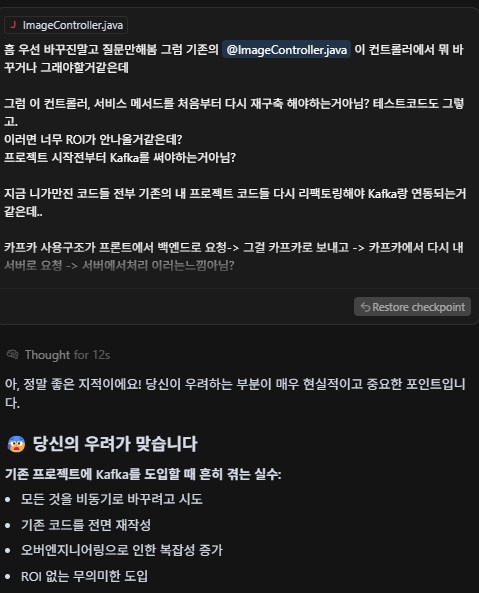
AI와의 문답3. 카프카를 이해하고 사용하고자 했으나 AI는 역시 기능A를 모든곳에 사용하려고 하는듯하다.. 아직까지 비즈니스 로직 사용은 인간이 판단해야하는 것 같다
