MusicBell (MSA + SSO)
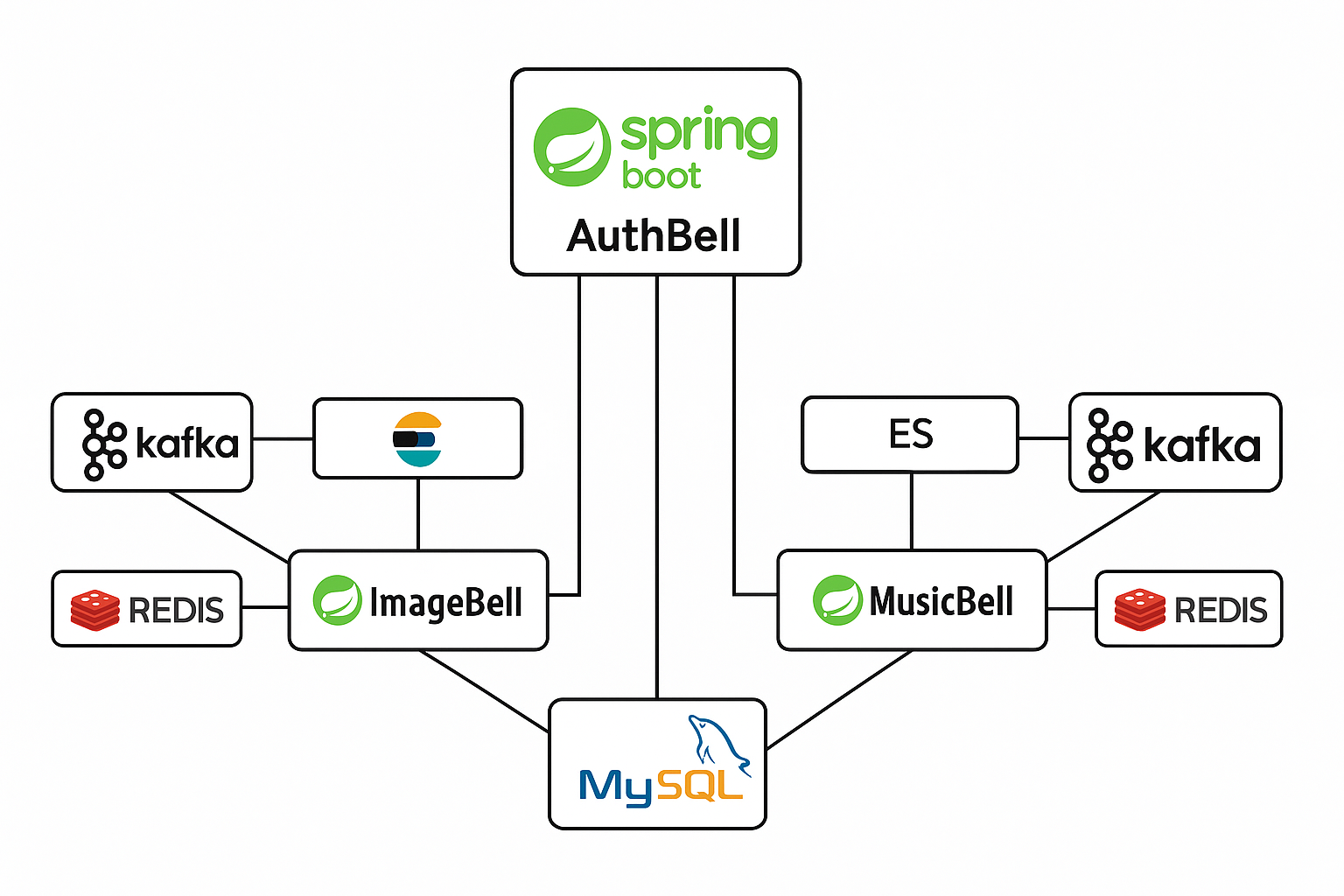
백엔드 아키텍쳐. 틀 을그리고 GPT에 생성요청했는데 좀 빠진게 듬성듬성.. 아무튼 기본적으론 Docker Compose위에서 이러한 MSA를 이루고 있다
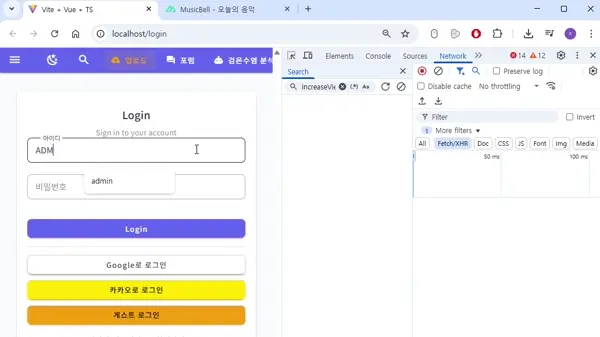
SSO완성 결과 1. ImgBell에 로그인해서 Cookie에 refresh, Access토큰을 저장 후 user정보도 localstorage에 저장하고있다. MSA의 한 서비스인 MusicBell도 쿠키에 저장된 모습. 새로고침 시 user정보도 역시 localstorage에 저장되고있다.
SSO완성 결과 2. 이번엔 MusicBell에서 로그아웃 시 Cookie와 user정보가 삭제되고 ImgBell에서도 Cookie가 삭제되어있다. user정보는 새로고침 시 삭제되고 토큰만료 안내alert를 출력하고있다.
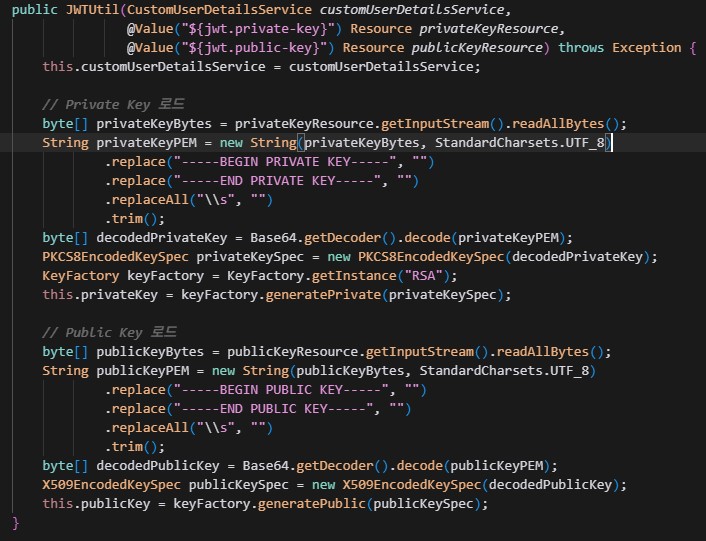
privateKey와 publicKey를 생성자로 로드하고있는모습. 저걸 뭐 누가 어떻게 외우나? 외울이유가 없다 이런건. 중요한건 작동원리.

Claude의 키생성과정 설명. 저게 뭔소린지 알아듣는사람 없을거다 중요한건 이 PrivateKey는 AuthBell만 갖고있는 도장이고, PublicKey는 모든 MSA서비스에 뿌리고 저 도장이 진짜인지 확인하는 "기계"같은것이다. 이렇게 JWT의 유효성을 안전하게 검증하는 것.
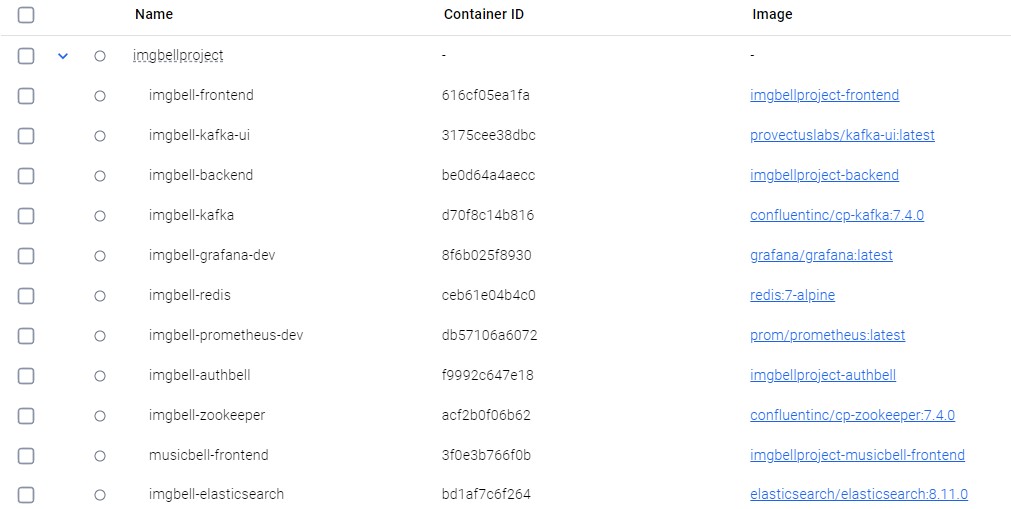
MSA의 도커환경. 정말.. 초대형 웹서비스는 어떻게 돌아가고 있을지 감도 안온다
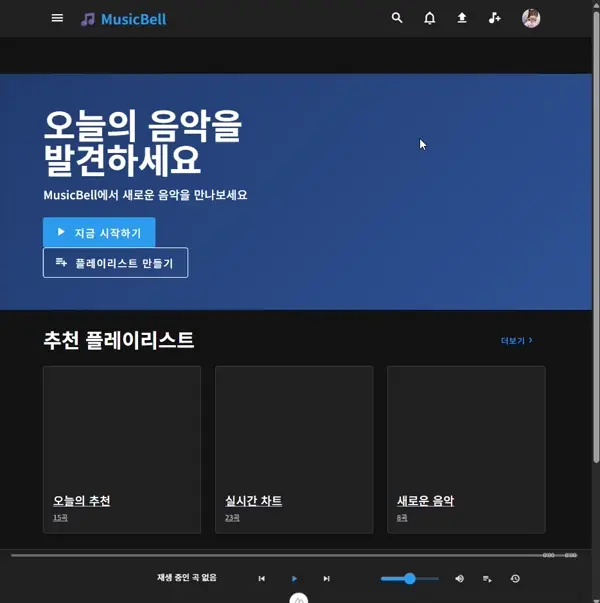
메인페이지. 여느 음악사이트와 같은 고정 하단플레이어, 재생목록, 최근들은목록을 구현했다.
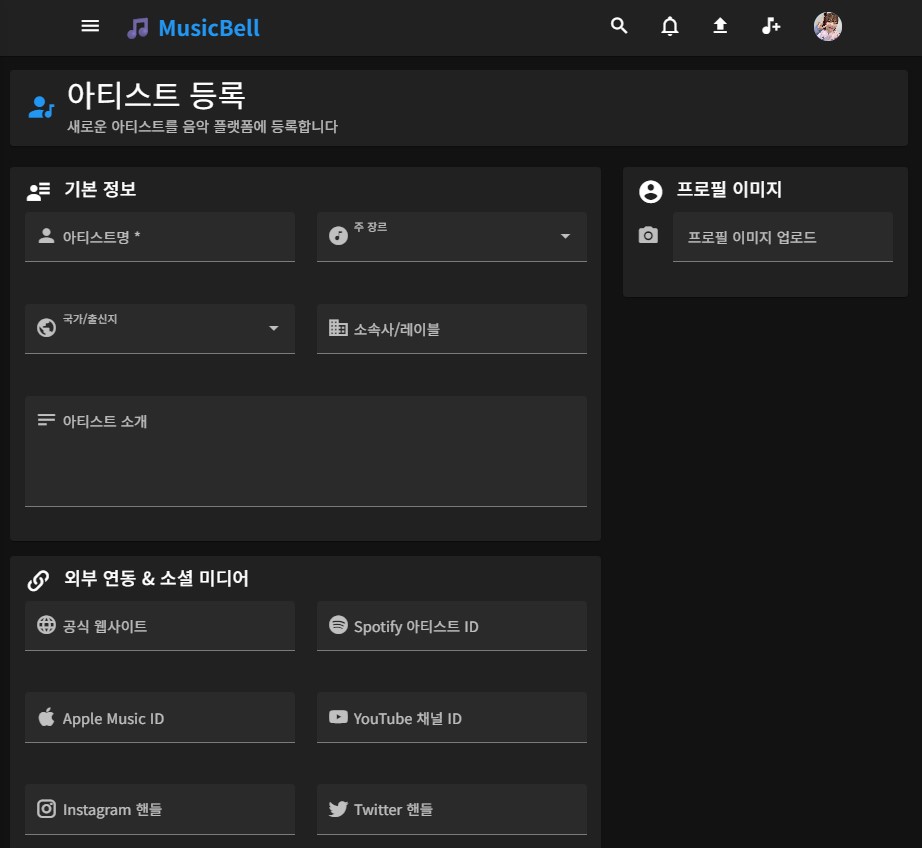
아티스트 업로드 페이지. 최초엔 Artist테이블은 추가하지 않으려 했다가 추후 여러 통계등에 사용할 것 같아서 추가했다.
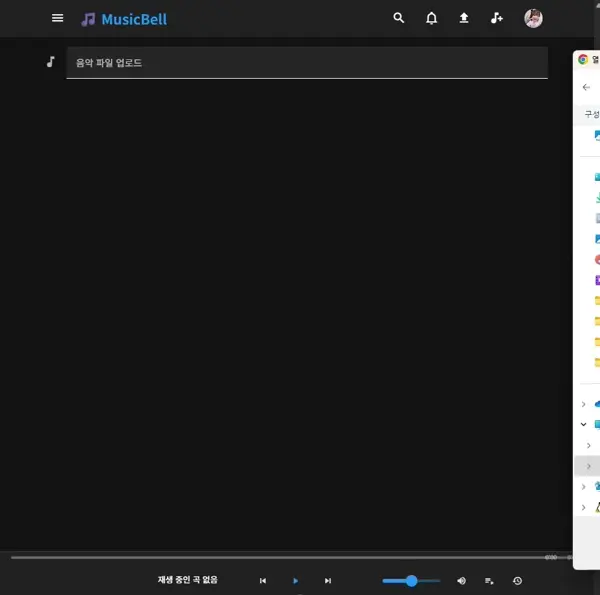
음악 업로드 페이지. 파일 업로드 시 기본적으로 재생시간, 아티스트명, 음악명 이 자동으로 기록된다. 아티스트의 경우 기존에 등록해놓은 아티스트에서 선택하는 방식이다. 기존 등록해놓지 않은 신인 아티스트라면 그냥 텍스트 입력으로도 임시OK
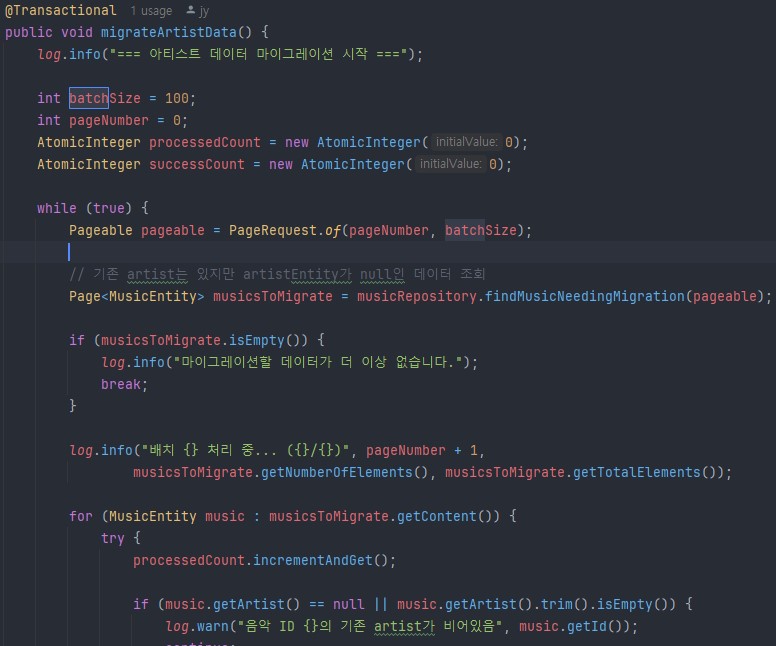
백엔드 마이그레이션 코드. AtomicInteger라는것도 처음보는 개념도 있었다.
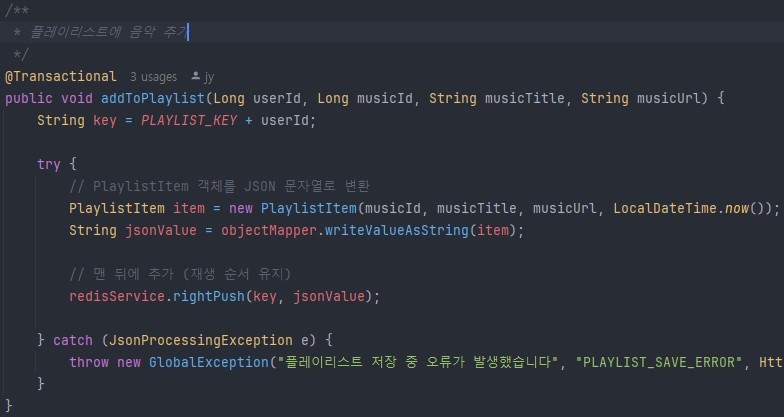
백엔드 Redis 플레이리스트에 음악정보를 추가하는코드. ImgBell의 코드를 재활용+리팩토링했고 동작원리, 큰그림을 이해하고 AI, 인터넷에 있는 정보들을 "지력"으로써 활용하면 간단하다.
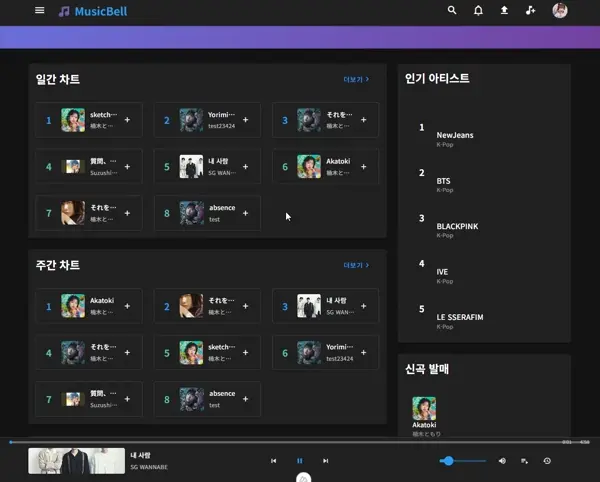
시간이라도 멈춘듯이 너무느리다. 일간, 주간, 월간 차트들을 로드하는데 20초? 유저들 다 빠져나가겠다!
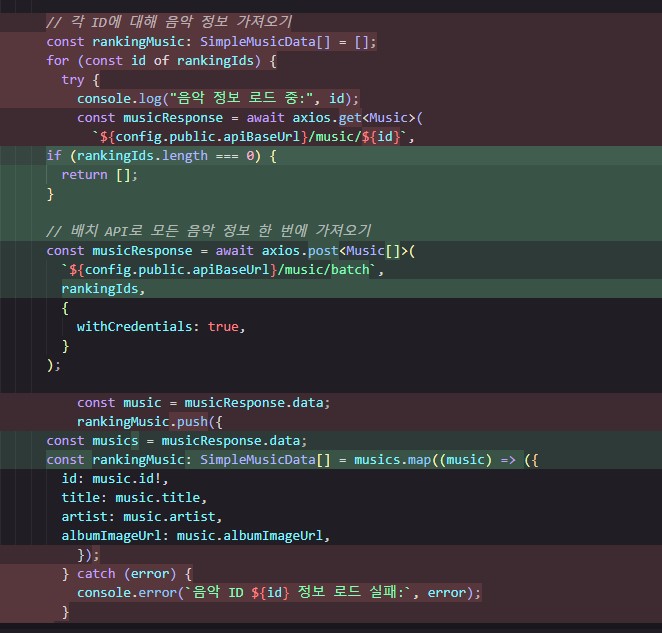
최초엔 Redis 캐시를 사용하는 최적화를 생각했으나, for문으로 데이터를 하나하나 불러오는게 문제같다고 최적화 솔루션 제공을 요청해봤더니 AI가 BATCH로 API를 사용하는 방식도 같이 추천해줬다.
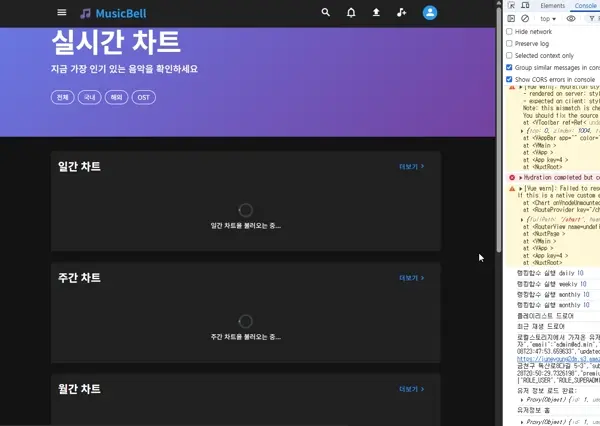
시간이라도 멈춘듯이 너무 빠르다!. BATCH를 활용하니 1초만에 뿅! 여기에 FrontEnd의 Cache까지 활용하면 API요청 비용도 절약할 수 있다. 이렇게 성능구현->최적화를 항상 염두해 두는 자세가 중요하다 AI는 이런 구조를 짜지 못하기에.
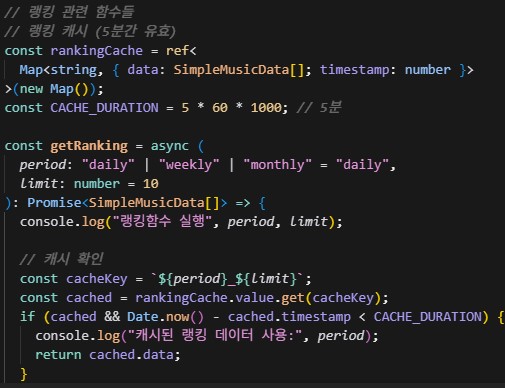
프론트 Cache코드. 프론트에서 캐시를 사용하는건 처음이었다. 백엔드까지 가지도않고 상당히 효율적인 방식을 AI가 추천해줬고 최적화 작업 할때 프론트선에서 Cut할 수 있는 방법도 내 무기로써 추가됐다.
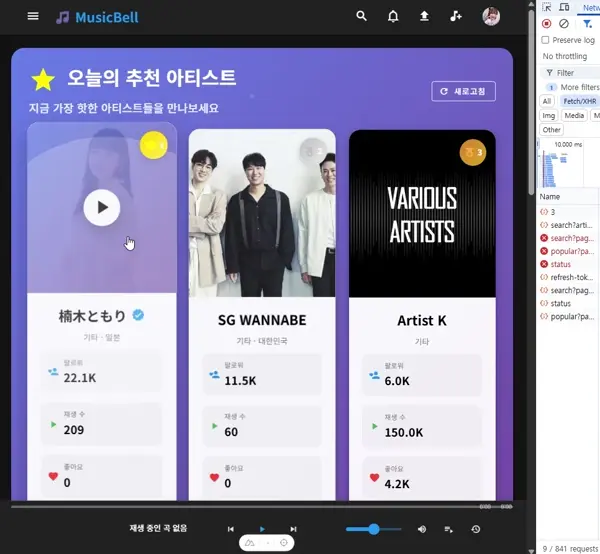
아티스트 메인페이지. 추천 아티스트 3명과 그 아래에 아티스목록 및 검색이있다. 더 보기를 클릭하면 서버로 9개의 아티스트 데이터를 추가요청 한다.
아티스트 디테일 페이지. 아티스트 업로드시에 받은 정보들(외부링크 등)과 해당 아티스트의 음악 감상이 가능하다. 추가적으로 뭐 Music테이블에 Album항목을 추가하여 앨범별로 음악들을 묶는다던지, 관련 아티스트등을 표시할 수도 있을 것 같다. 결국 이런 "무슨 기능을 어떻게 구현하나"를 생각하는게 중요한 것 같다.
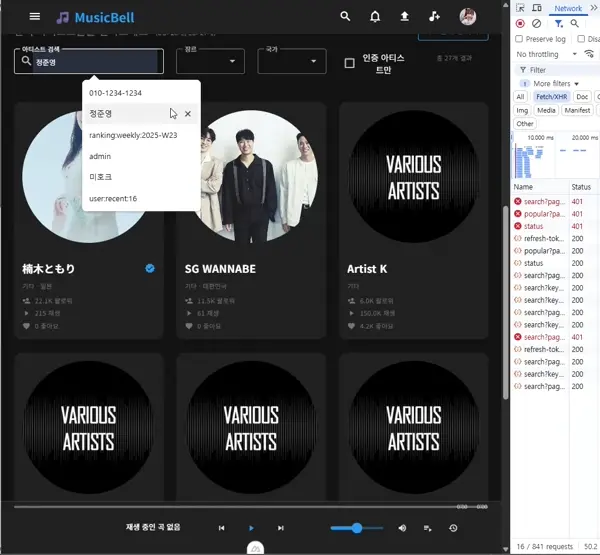
엘라스틱 서치 활용. 그냥 보기에는 "Like 검색이랑 뭔차이여"일진 모르겠지만 데이터가 많아질수록 UX의 질은 차원이 다를 것이다.
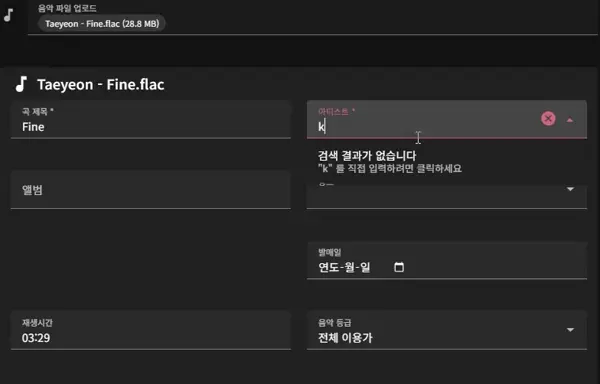
Artist Upload기능에서도 ES를 사용했다. autocomplete 기능으로 해당하는 아티스트를 바인딩 하고있다.
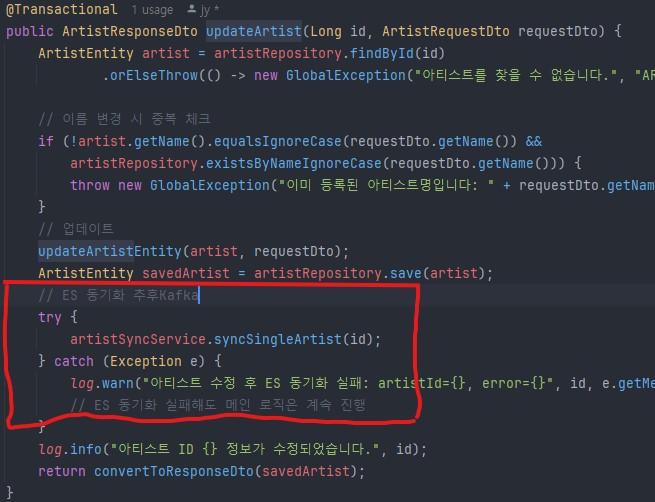
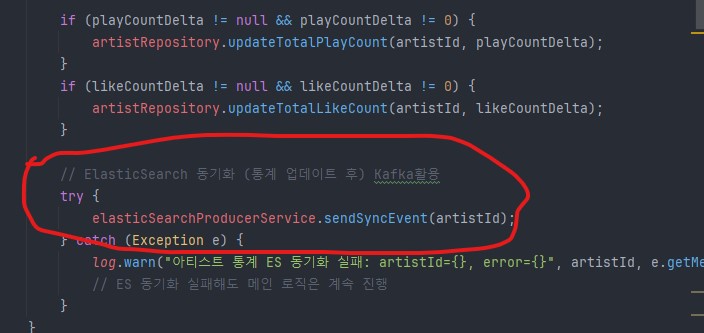
4. 엘라스틱 서치때에 설명 했다시피 미리 Kafka를 사용할 법한 장소에 이렇게 주석으로 마킹해두면 나중에 할일이 편해진다. 뭘 말하고싶냐?-> 백엔드에 있어서 미리미리 구조를 설계해놓으면 여러모로 편하다 라는것. 물론 인간이 하나하나 치밀하게 다 할 수 없는 노릇이지만, 그런 자세를 항상 염두해두자 라는 의식이 중요하다.
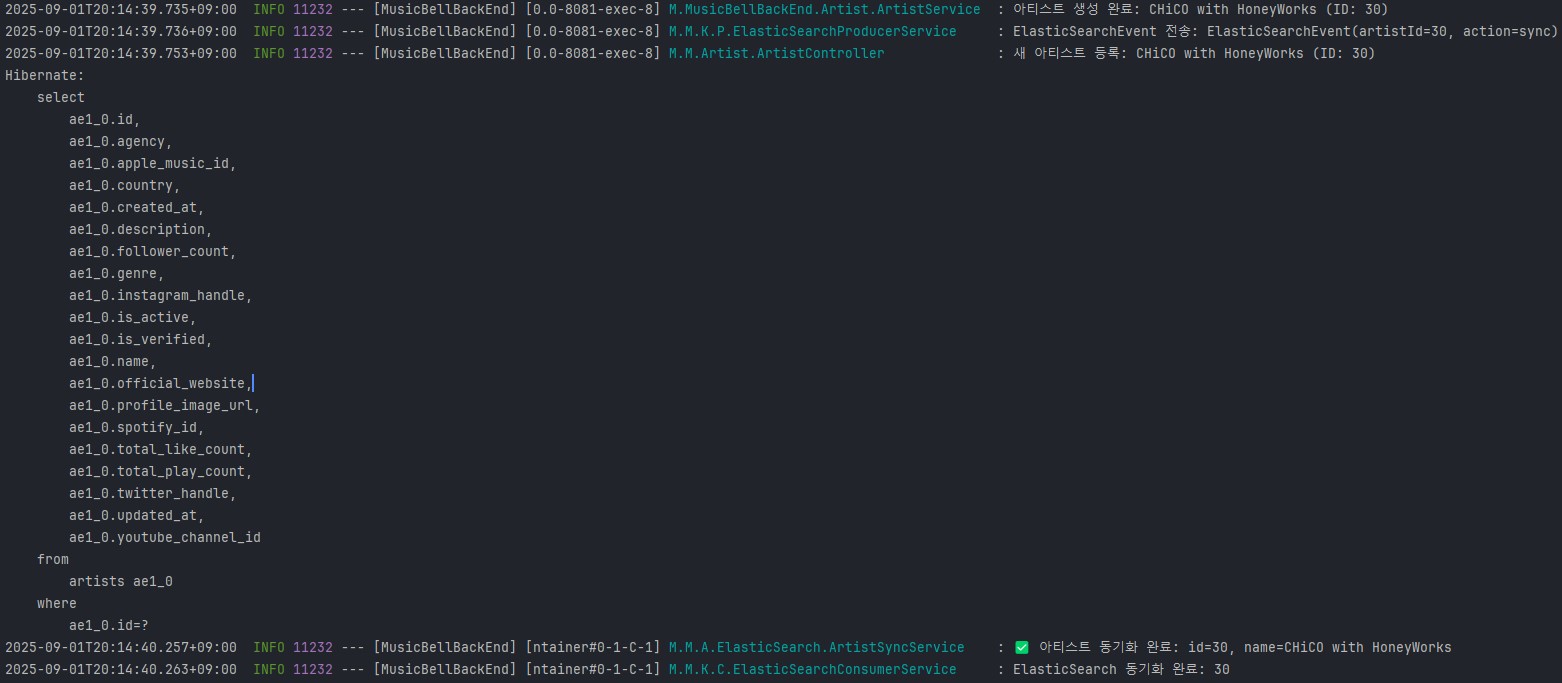
Artist를 Upload하면서 백엔드에 기록된 로직. 새아티스트를 DB에 저장하고있고 -> ElasticSearch Event를 전송하여 Kafka로 비동기 처리로직도 실행하고있다. DB에서의 쿼리문이 발동되어 저장이 된 후에 Kafka에서 아티스트 ES 인덱스 동기화가 완료되고 있는 모습이다. 즉 서비스로직 -> 즉시응답 -> Kafka비동기처리 실행. 이라는 순서가 잘 지켜지고 있다는 것.
Artist Upload 및 ES 인덱스 동기화가 가 끝난 후 아티스트 목록에 새로 데이터가 추가된 모습.
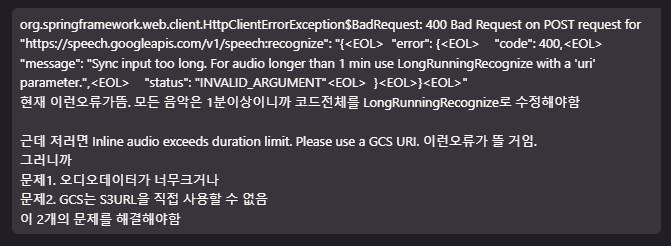
우선 Gemini Text To Speech API도 시도해봤으나 AI가 저 문제의 루프를 해결하지 못하고 헛돌기만했다. 수작업과 지시로 어떻게든 고쳤으나 API가 제공하는 데이터의 질이 너무 떨어져서 OpenAI로 변경하기로 마음먹었다.
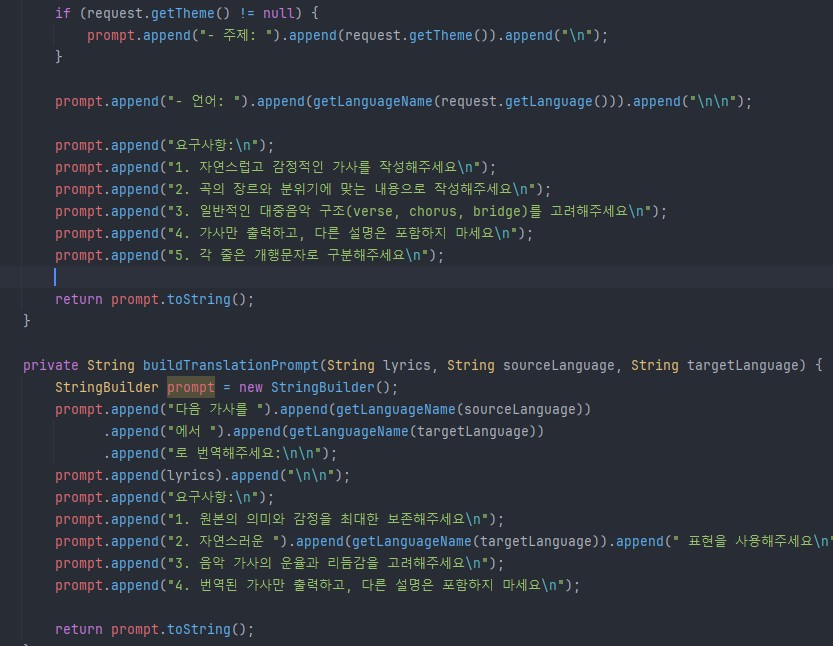
AI Agent가 비즈니스 의도를 이해하지 못하고 뭔 가사 창조를 하고있다. 이게 인간과 AI의 가장 큰 차이인 물리세계에 존재하지 않음으로써 일어나는 격차라고 생각한다. "대체 왜 가사를 니멋대로 창조해?"

이 작업도 여러실패를 거쳤다. 위 스크린샷은 일단은 Whisper에게서 가사를 받아오는데에 성공한 스텝1 클리어 스크린샷. 하지만 라인 파싱에 실패하고있다.
그냥 가사 자체를 통째로 받아오고 가사 라인 파싱 및 수정은 인간이 상세하게 수작업으로 할 수 있도록 지시했다. 몇 번이나 중요하다고 느끼는 인간이 해야할 구조, 설계 작업이다.. 근데 이 작업은 우연이 겹쳐서 놀라운 부분이 있었다(최하단)
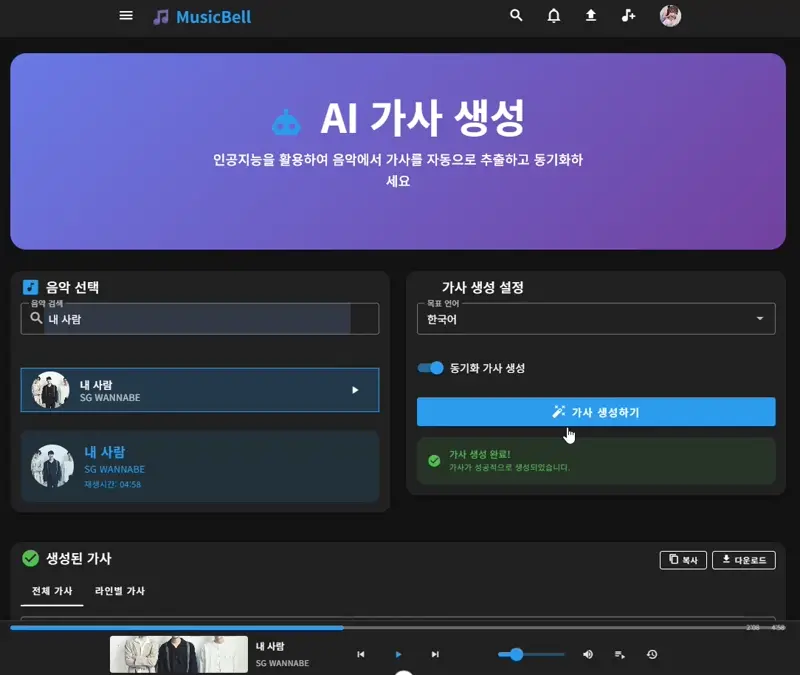
가사추출 성공1. 상세히 들여다보면 뭐 다른점도 있기에 사람이 상세하게 수정한 후 DB에 업로드해야할 것이다. 가사 한줄한줄 프론트에 바인딩도 성공한 모습.
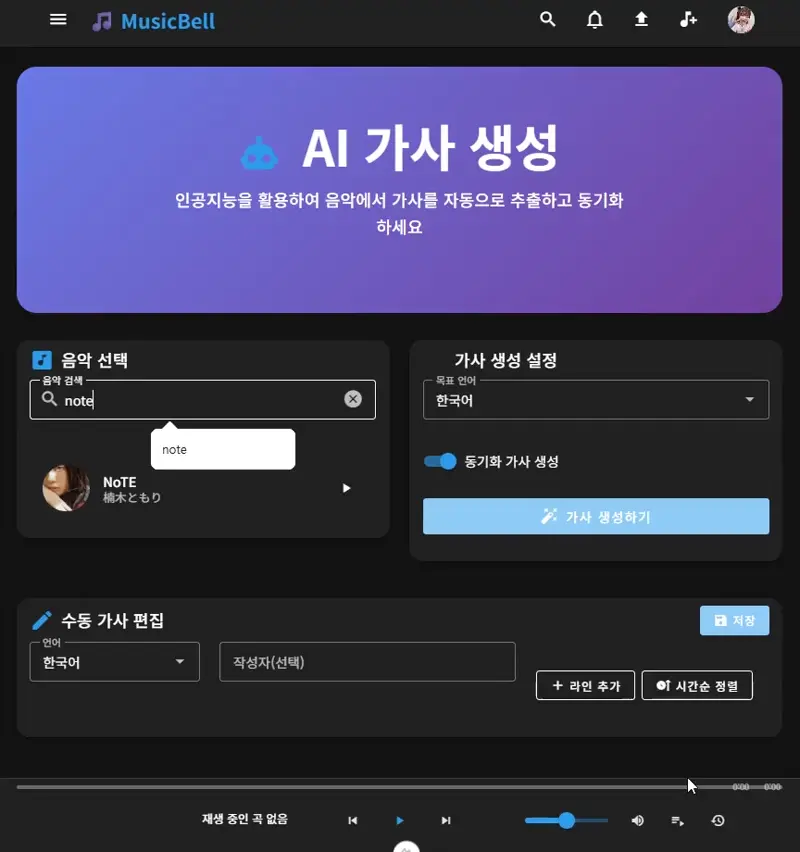
가사추출 성공2. 일본어로도 정상적으로 가사를 생성 및 바인딩하고있다. 시작과 끝시간은 밀리초단위에서 초단위로 변경->MusicEntity의 duration과 일관성을 확보함으로써 음악 스트리밍과 동시에 음악+가사 스트리밍도 편하게 바인딩 할 수 있었다.
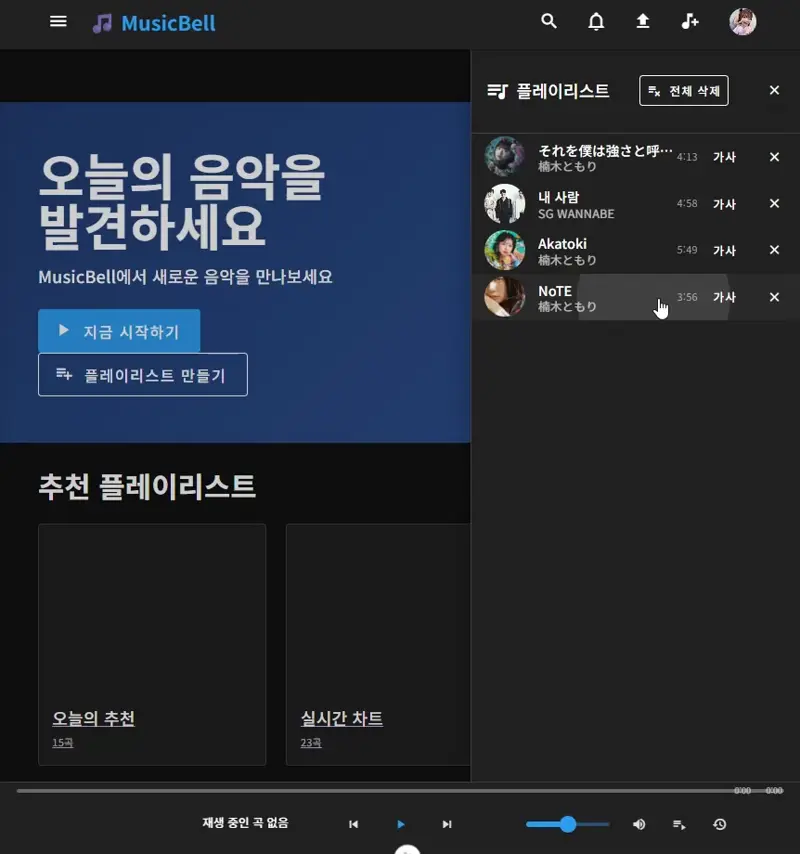
가사 컴포넌트를 끼워넣고 의도한대로 실시간 가사또한 작동하는모습. 심심하면 뭐 폰트색깔이나 디자인을 바꿔도 좋을 것 같다.
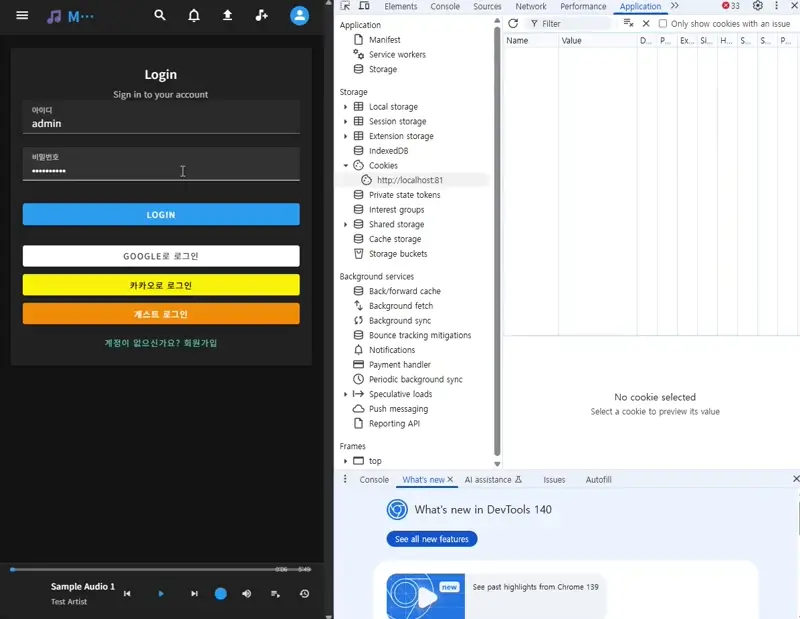
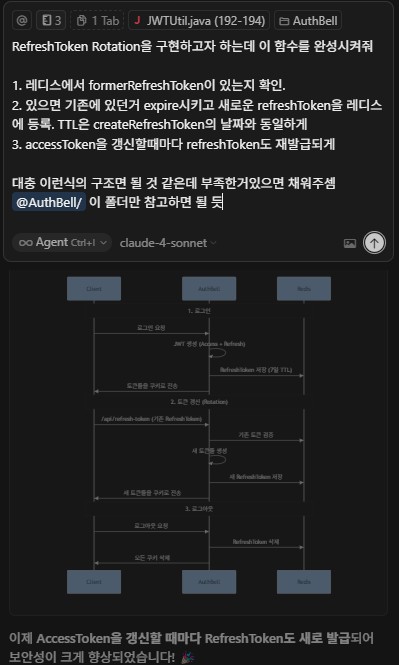
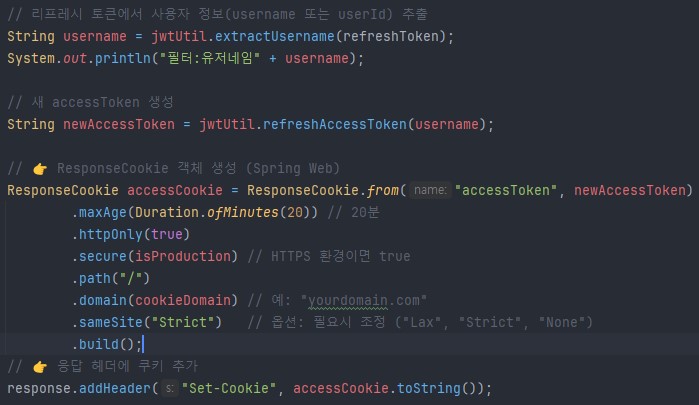
RefreshToken Rotation이 구현돼있는모습. accessToken갱신 후 확인해보면 기존의 RefreshToken의 값이 변경되어있다.

Docker컨테이너 로그에도 잘 기록되어있는 모습. 근데 난 이 Redis나 DB에 JWT를 저장하는게 너무 회의적이다.. 물론 보안이 중요한곳에는 필요하겠지만 JWT최대의 장점이자 철학인 Stateless를 포기하기하는게 뭔가 찜찜해 죽겠다.. "굳이???... 굳이?!?!?!!?"라는 생각이 자꾸 머리속에 맴돈다.
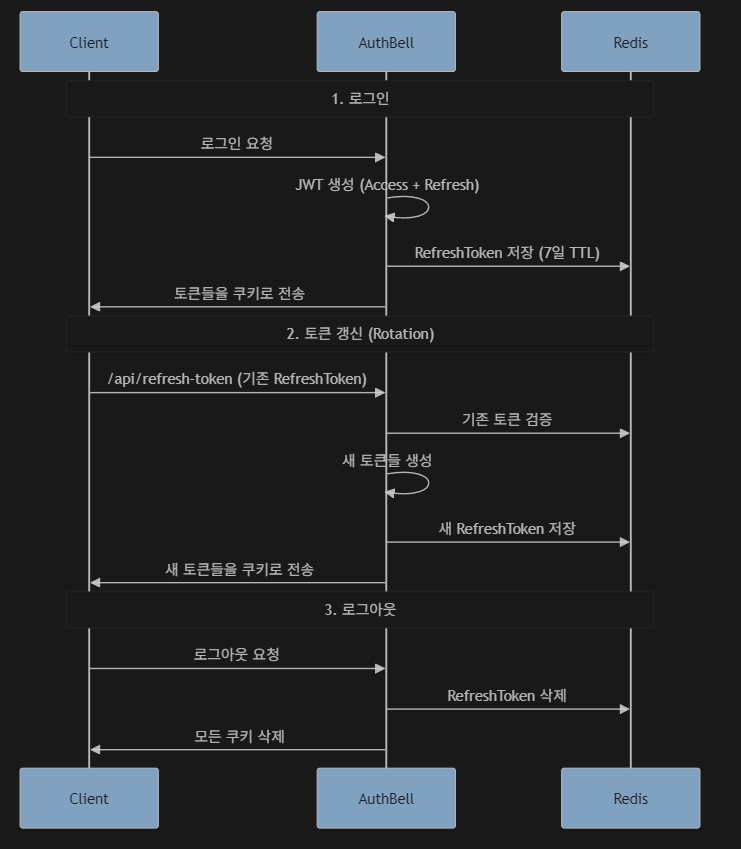
RefeshToken Rotation 동작흐름.
쿠키에서 기존 AccessToken을 삭제하고 Authorization Header에서 관리하고있다. XSRF토큰은..CSRF토큰 구현중의 잔재 무시하자.